Section 1 - A¶
How to read this section?
- Section Headers (In Bold) to segregate the main categories.
- Sub Headers to represent the respective section explained by sensei in the video
- The code snippet breakdown: Till that point along with explaination on what was done. The final code snippet is in the
Train.pyfile.
Introduction¶
We will be reproducing the GPT 2 model that was released by OpenAI based on their paper and the source code released. We will be working on the 124 million parameter model, which was the smallest of the mini-series which was released- So, during each release, mini models are made i.e. from smaller parameters to larger ones. And usually the larger ones end up being THE "GPT Model".
The source code of GPT 2 provided by OpenAI was implemented in TensorFlow, but we will be implementing it in PyTorch.
We can even load this model from the HuggingFace library as then we can even access all the parameter value settings that was provided to that original 124M model.
Now, the original implementation code was very complex and hard to understand, so we will be doing our own implementation and building it from scratch to reproduce it. But what our first step will be, is to load the original 124M model from HuggingFace itself into OUR CLASS, therefore we are importing all of the properties, especially the weights and the parameters. So we are ensuring we are within the same environment as the original code but will be doing our own implementation.
from dataclasses import dataclass
import torch
from torch import nn
from torch.nn import functional as F
#=========================================================
@dataclass
class GPTConfig:
block_size: int = 256
vocab_size: int = 85
n_layer: int = 6
n_head: int = 6
n_embd: int = 384
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
To start with, in the GPT 2 paper they have made slight adjustments to the original transformer model implementation (As seen in the below image), i.e. The Encoder section and The Cross-Attention block which actually utilises the encoder section, itself are completely removed. Therefore GPT Architecture is known as a Decoder only architecture model.
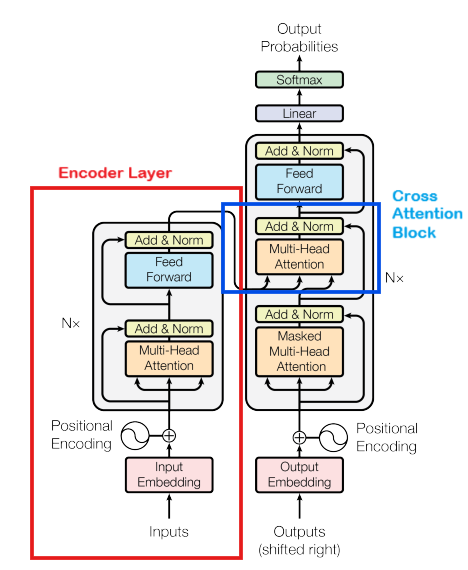
Everything else will remain the same, but there will be some differences that we will implement.
In the GPT 2 paper, in page 4 under section 2.3 Model they have mentioned "Layer normalization (Ba et al., 2016) was moved to the input of each sub-block, similar to a pre-activation residual network (He et al., 2016) and an additional layer normalization was added after the final selfattention block.".
So basically there have been some reshuffling of the order of the layers and the addition of a layer which are:
The Norm Layer (layer norm - ln) is added before the Multi-Head attention layer
One more Norm Layer (layer norm - ln) has been added before the final section of the model i.e. after the self-attention block and before Linear-Softmax layers.
Implementing the GPT-2 nn.Module¶
Now, we will be implementing our nn.Modules and we will be using the schema reference of the GPT 2 model which we loaded from HuggingFace in section 0, which were:
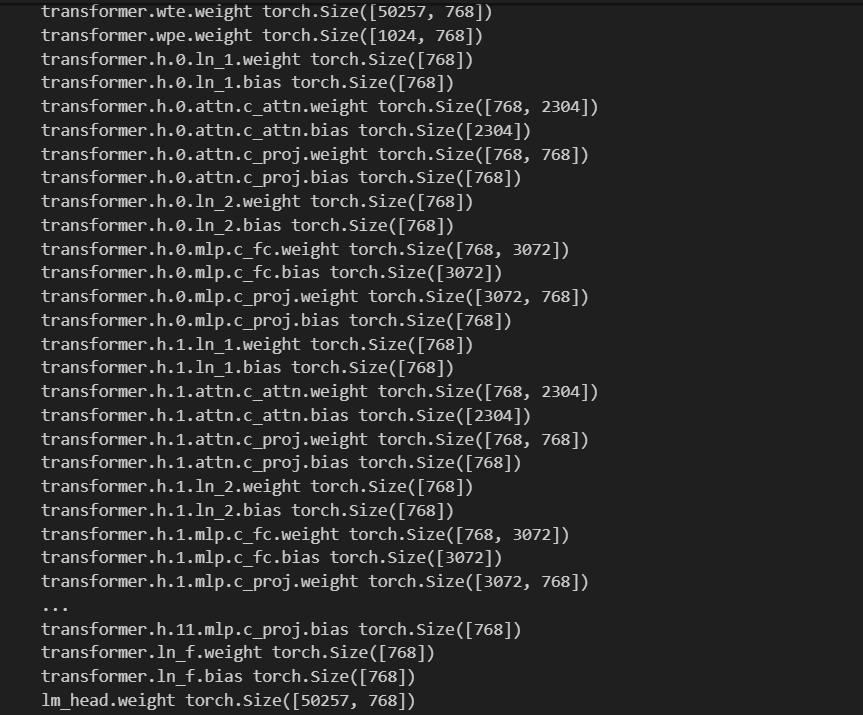
So our aim would be to match up/replicate the above schema.
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd)
))
self.lm_head = nn.Linear( config.n_embd, config.vocab_size, bias=False)
self.transformer = nn.ModuleDict(dict())
In the above schema image we see that the main container which contains all the modules in called 'transformer', therefore that is what we have declared first.
We are then reflecting the
transformermodule usingnn.ModuleDictwhich basically allows you to index into the sub-modules using keys, just like in a dictionary. Our keys are basically strings.
Then within that transformer module we have-
wte = nn.Embedding(config.vocab_size, config.n_embd) and wpe = nn.Embedding(config.block_size, config.n_emb)
which are the tensor and positional embeddings respectively.
both of these modules are
nn.Embeddingmodules, and ann.Embeddingmodule is just a "fancy wrapper module" for a single array/list/block of numbers, so they just a single tensor.so
nn.Embeddingis just a glorified wrapper around these tensor that allows you to access its elements by indexing into their rows.
h = nn.ModuleList([Block(config) for _ in range(config.n_layer) ])
in the schema you can see that
his being declared, but the indexing is happening through an integer value i.e. from 0 to 11 (unlike the other modules where indexing was through a string).therefore we declare it as a List
nn.ModuleListso that we can index it using integers exactly as we see in the schema.now the
hmodule, the module list has an_layerBlocks, theBlocksstill need to be defined (we will in a while).the
hprobably stands for 'hidden'
ln_f = nn.LayerNorm(config.n_embd)
- this is based on us following the GPT 2 paper where we have to define the additional 'Final Layer Norm', so thats what we have done.
So that is the end of the Transformer Module. After that, we have the final Classifier, which is-
self.lm_head = nn.Linear(config.vocab_size, config.n_embd, bias=False)
- The final classifier, which is the Language Model Head (lm_head) which projects the number of embeddings (n_embd, which is 786 in the image) all the way to the vocab size (vocab_size, which is 50257 in the image) and GPT 2 uses no bias for this final projection.
Therefore this is the skeleton structure of what we saw in the architecture diagram! Below is a breakdown of it for a clearer understanding:
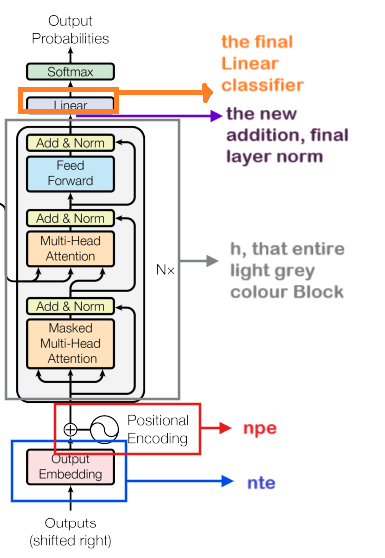
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CasualSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
Here we have implemented the Block Module.
All the initializations have been done based on the schema: (ln_1) self.ln_1 = nn.LayerNorm(config.n_embd), (attn) self.attn = CasualSelfAttention(config), (ln_2) self.ln_2 = nn.LayerNorm(config.n_embd) and (mlp) self.mlp = MLP(config).
And as discussed the order of the implementation of the attention, mlp and ln layers are different, which is what we are seeing here. The ln_1 is fed into attn and then ln_2 is fed into mlp.
Note: There was another point mentioned here by sensei that, if you look at the diagram, the layer norm of the previous block were fed into the next layer as well, as residuals. But turns out that is not desirable. There we are doing them seperately itself. We are also keeping in mind what we learnt in Micrograd, where during backpropagation, the gradients are passed equally across the NN when there is an addition '+' operation.
Attention self.attn:
You will recall that Attention is a communication operation, it were all the tokens (and we will have like 1024 tokens lined up in a sequence) communicate, this is where they exchange information.
So Attention is a Aggregation function, its a Pooling function, its a weighted sum function, it is a reduce operation.
MLP self.mlp:
- In this MLP, happens to every single tokens induvidually. There is no information being collected or exchanged between the tokens.
Overall: You can say that (or think of this as) the attention is the Reduce and the MLP is the Map. And what you end up with is the transformer just being a repeated application of Map-Reduce.
So,
Attention is where they communicate.
MLP is where they think induvidually based on all the information they have gathered.
And every one of these blocks interatively (i.e. in
x = x + ... ((x))) refines the representations at the residual stream.
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
Note for me (Need to come back to this - IMP)
The following points weren't very clear for me or need revision on: The Residual stream, Map Reduce.
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate='tanh')
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x
Now, we implement the MLP Module block.
Here we have two Linear layers (c_fc and c_proj) being sandwiched between GELU non-linearity.
NOTES:
Since we are doing a reproduction of GPT 2, we are going ahead with this approach.
GELU is you can say an upgrade or a softer output curve than that of ReLU (which is preferable as we have seen before how ReLU can give us undesirable outcomes as its values are always like flat to 0 until it lineraly shoots up - The 'Dead ReLU Neuron problem'). The research paper which introduced GELU can be read from here.
GELU can be read more on from the PyTorch documentation, there is the original version which is like the default (the first equation you see in the pytorch docs) and is normally prefered during the modern implementation. But since we are following GPT2, we are using what OpenAI used, the
tanhapproximation version (the second equation you see in the pytorch docs).So, right now, in more modern networks like Llama3 and so on, different non-linearities are used, like alternatives to GELU.
Note for me (Need to come back to this - IMP)
The following points weren't very clear for me or need revision on: Why the parameters have 4 multiplied alternatively, How do we know or why are those 2 as Linear layers and Why there is a Non-linear sandwiched between.
import math
class CasualSelfAttention(nn.Module):
def __init__(self, config):
super.__init__()
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size()
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
attn = (q @ k.transpose[-2, -1]) * (1.0 / math.sqrt(k.size[-1]))
attn = attn.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
attn = F.softmax(attn, dim=1)
y = attn @ v
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.c_proj(y)
return y
Above code cell is the implementation of the Attention Block. Now, we have seen in the GPT 1 implementation that the Attention Block is basically Multiple Attention Layers running in parallel. So the outputs of all of those are just concatenated together which produces the out as the output from the MultiHeadAttention layer.
Unlike in that implementation, where there were many modules like Head and Multi Head, here we have just put them into one i.e. CasualSelfAttention module.
Note: Here the transpose and split functions are being personally experimented and calculated by sensei (as he calls it "done some gymnastics"), so its perfectly fine if you don't get everything to the CORE detail. But most of it can be broken down as I will do now :)
Above code cell Breakdown:
We have these tokens lined up in a sequence. Each of those tokens, in this stage i.e. in Self-Attention, emits three vectors: Query, Key and Value.
First what happens is that, the Queries and Keys multiply each other, so as to get the attention amount i.e. how interesting they find each other. So they have to interact multiplicatively.
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
So above, we have calculated the qkv and split it, then the bunch of "gymnastics" will follow.
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
This is what is ultimately happening: (B, nh, T, hs). So the way that works is:
- We are making the number of heads
nhinto a batch dimension. So it becomes a batch just likeB. This way, in the operations that will follow from now, pytorch will treat(B, nh)as batches and it will apply all of the operations, on all of them, in parallel, in both the batch and the heads.
The Operations that will follow:
attn = (q @ k.transpose[-2, -1]) * (1.0 / math.sqrt(k.size[-1])): the queriesqand keyskinteracting (matrix multiply@) to give us the attentionattn.attn = attn.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf')): this is the auto-regressive mask that make sure the current token only attend to tokens before them and never the ones in the future.attn = F.softmax(attn, dim=1): The softmax layer here normalises the attention, so it sums up to 1 always.y = attn @ v: is where we do a matrix multiply of the attention with the values, which is where we get the weighted sum of the values of the tokens which we found interesting-- at every single token.y = y.transpose(1, 2).contiguous().view(B, T, C): is basically the reassembling of all of them again, so this is essentially performing the concatenation operation.
Milestone checkpoint!
- At this stage, RIGHT HERE, RIGHT NOW we have COMPLETED THE GPT 2 IMPLEMENTATION!. This was the entire setup which was done in less than 100 lines of code in contrast to HuggingFace's 1000.
- Now we can go ahead and take all the weights directly from the model we took from HF (thats why we even kept the naming same), set them and then do generation.
Loading the huggingface/GPT-2 parameters¶
class GPTConfig:
block_size: int = 1024 # max sequence length
vocab_size: int = 50257 # number of tokens: 50,000 BPE merges + 256 bytes tokens + 1 <|endoftext|> token
n_layer: int = 12 # number of layers
n_head: int = 12 # number of heads
n_embd: int = 768 # embedding dimension
Now, before we go ahead with importing the parameters from HF and loading the model, we have also changed the values of our parameters, which is what you see above.
Also note, the breakdown of vocab_size can be understood better once we also finish with the Tokenization video.
@classmethod
def from_pretrained(cls, model_type):
"""Loads pretrained GPT-2 model weights from huggingface"""
assert model_type in {'gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl'}
from transformers import GPT2LMHeadModel
print("loading weights from pretrained gpt: %s" % model_type)
# n_layer, n_head and n_embd are determined from model_type
config_args = {
'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params
'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params
'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params
'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params
}[model_type]
config_args['vocab_size'] = 50257 # always 50257 for GPT model checkpoints
config_args['block_size'] = 1024 # always 1024 for GPT model checkpoints
# create a from-scratch initialized minGPT model
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith('.attn.bias')] # discard this mask / buffer, not a param
# init a huggingface/transformers model
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# copy while ensuring all of the parameters are aligned and match in names and shapes
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')] # ignore these, just a buffer
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')] # same, just the mask (buffer)
transposed = ['attn.c_attn.weight', 'attn.c_proj.weight', 'mlp.c_fc.weight', 'mlp.c_proj.weight']
# basically the openai checkpoints use a "Conv1D" module, but we only want to use a vanilla Linear
# this means that we have to transpose these weights when we import them
assert len(sd_keys_hf) == len(sd_keys), f"mismatched keys: {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
if any(k.endswith(w) for w in transposed):
# special treatment for the Conv1D weights we need to transpose
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else:
# vanilla copy over the other parameters
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model
Okay so here, we dont really have to go for a detailed breakdown of the code. Its the standard one when it comes to loading models.
At the start we load the model from HF as we saw in Section 0, we need to select from one of the model options, creating its own state dict, ignoring the buffers (.attn.bias) and finally we transpose some of the weights (something interesting happened here btw) - this part was hard coded by sensei as the usual code was done in tensorflow, so this was modified by him so that it fits our usecase.
model = GPT.from_pretrained('gpt2')
print("didn't crash yay!")
Debugging moment, yay! (part 1)¶
After having done that, we tried to run the python script to see if we are able to load the model from HF into our GPT nn.Module successfully. We did in the end! But there were two hiccups we faced on the way, which i wanted to add here to show how the smallest of details matter.
TypeError: descriptor '__init__' of 'super' object needs an argumentin CasualSeltAttention Module. The issue was i had writtensuper.__init__()which had to besuper().__init__()AssertionError: assert sd_hf[k].shape == sd[k].shape(Here is where the interesting part happened as i mentioned). So, there was some issue with the values. There were multiple reasons, so inorder to find the root cause, we (we as in, me and chatgpt ofcourse) modified the code given by sensei and printed the values that are actually been passed (his original part of that code is commented in the train.py file). Like this:
for k in sd_keys_hf:
if any(k.endswith(w) for w in transposed):
assert sd_hf[k].shape[::-1] == sd[k].shape, f"Shape mismatch (transposed): {k}, {sd_hf[k].shape[::-1]} vs {sd[k].shape}" #Here
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else:
assert sd_hf[k].shape == sd[k].shape, f"Shape mismatch: {k}, {sd_hf[k].shape} vs {sd[k].shape}" #Here
with torch.no_grad():
sd[k].copy_(sd_hf[k])
Then we noticed that the transposed values werent matching, they were switched: Shape mismatch: lm_head.weight, torch.Size([50257, 768]) vs torch.Size([768, 50257]).
And upon further debug I saw that in the GPT.init() in lm_head i had switched the order of the parameters self.lm_head = nn.Linear(config.vocab_size, config.n_embd, bias=False) # ❌ current incorrect, therefore it was switched: self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False).
So yeah, that was some fun and "I definetly didnt freak out for a moment" 10 minutes of debugging haha.
Implementing the forward pass to get logits¶
Before we are able to generate something from the model, need to forward it. So we'll write the forward() function now.
def forward(self, idx, targets=None):
# idx is of shape (B, T)
B, T = idx.size()
assert T <= self.config.block_size, f"Cannot forward sequence of length {T}, block size is only {self.config.block_size}"
# forward the token and posisition embeddings
pos = torch.arange(0, T, dtype=torch.long, device=idx.device) # shape (T)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (T, n_embd)
tok_emb = self.transformer.wte(idx) # token embeddings of shape (B, T, n_embd)
x = tok_emb + pos_emb
# forward the blocks of the transformer
for block in self.transformer.h:
x = block(x)
# forward the final layernorm and the classifier
x = self.transformer.ln_f(x)
logits = self.lm_head(x) # (B, T, vocab_size)
return logits
In the forward function we are passing indeces idx (our tokens, i.e. token indeces) which are the independent tokens. And these are of the size/shape (B, T).
Now, here we are making like a two dimensional storage of how these tokens will be processed. So there is one batch (consider it as one array) of size batch_size, in each batch the tokens T gets filled in a sequence. Like that, we will have multiple batches all stacked up. Therefore, assert T <= self.config.block_size.
Next set of codes we are forwarding the positional and token embeddings:
pos = torch.arange(0, T, dtype=torch.long, device=idx.device): here we are usingarangewhich is a version of range but in PyTorch. We will be iterating from0 to T, creating this kind of positional indeces.Next we have the positional embeddings
pos_emb = self.transformer.wpe(pos), the token embeddingstok_emb = self.transformer.wte(idx)and the addition of those twox = tok_emb + pos_emb. We need to remember here that the positional embeddings are going to be identical for every single row, so in that addition operation there is broadcasting happening (see the comments part for the size of the two variables in the above code snippet). Therefore an additional value gets created inpos_embso that those two get add up, because the same positional embeddings get applied at every single row of examples stacked up in the batch.Next we forward the tranformer blocks
h, the last layer normln_fand finally thelm_head(as we made in our GPT module class).What comes out after the forward is the
logits. Now, since our input is (B, T) indeces, then for every single (B, T) we will calculate the logits for what token comes next in that sequence. So "what is the token (B, T+1), the one on the right of this tokenT?". Thevocab_sizeis the number of possible tokens. Therefore(B, T, vocab_size)is the tensor that we are going to obtain.Right now, these
logitsare just a softmax away from becoming probabilities.
So, this was the forward pass of our network and we are getting our logits, now we should be able to generate from our model immediately :) (or so i thought haha).
Sampling init, prefix tokens, tokenization¶
So there is just one step left before we start sampling. We are going to do the same setup as we did in section 0 with huggingface, where we load the model, sample 5 times with a token limit of 30 characters. So that is exactly what we are going to do now.
The following code from section 0 is what we are going to write:
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
Following is our implementation of the above code:
num_return_sequences = 5
max_length = 30
model = GPT.from_pretrained("gpt2")
model.eval()
model.to("cuda")
We are defining the number of rows and the maximum context length that we want our model to generate
num_return_sequences = 5andmax_length = 30We are calling the model itself here, both
GPTand.from_pretrained("gpt2")have been defined by us above!Then we are setting the model to evaluation mode
model.eval()which is often considered as a good standard practise. Although sensei mentions that it won't really have much of an effect in our case as of now, as our model doesn't have different behaviours for either training or evaluation time. So batchnorm, drop out, none of those have been implemented as layers. The layers that we have should be identical during both training and eval time. But we are still using it as we are assuming that the pytorch internals does something clever during the eval mode.Finally, we are moving our model to run on CUDA
model.to("cuda")
import tiktoken
enc = tiktoken.get_encoding("gpt2")
tokens = enc.encode("Hello, I'm a language model,")
tokens = torch.tensor(tokens, dtype=torch.long) #8
tokens = tokens.unsqueeze(0).repeat(num_return_sequences, 1) #(5,8)
x = tokens.to("cuda")
Here, our aim is to set a prefix tokens like how we did in section 0, where we added the initial line "Hello, I'm a language model,".
We import the tokenizer by openai
import tiktokenand import the encoder used for gpt2enc = tiktoken.get_encoding("gpt2")Then we provide the prefix text that we want to be encoded into the tokeniser
tokens = enc.encode("Hello, I'm a language model,")Then we convert the tokens produced into tensors
tokens = torch.tensor(tokens, dtype=torch.long)(You can check what tokens were produced by the tokeniser using this site). So in this case we have8tokens that were produced.Then we are replicating it to 5 rows
tokens = tokens.unsqueeze(0).repeat(num_return_sequences, 1)Finally we are passing it to the CUDA machine. The
xhere inx = tokens.to("cuda"), is the indexidxthat goes into the forward pass of the GPT, processes the tokens and produces thelogitswhich contains the 9th token i.e. the tokens which were generated/predicted when the prefix text was passed to it.
Sampling loop¶
Now we will be writing a sampling loop to generate from this model.
# Right now x is (B, T) where B = 5, T = 8
# seed is set to 42, to follow with sensei in the video
torch.manual_seed(42)
torch.cuda.manual_seed(42)
while x.size(1) > max_length:
# forward the model to get the logits
with torch.no_grad():
logits = model(x) # (B, T, vocab_size)
logits = logits[:, -1, :] # take the logits at the last position | is now (B, vocab_size)
probs = F.softmax(logits, dim=-1) # get the probabilities
# do top-k sampling of 50 (something which HF pipeline had as default)
topk_probs, topk_indices = torch.topk(probs, 50, dim=-1) #topk_probs is (5, 50), topk_indices is (5, 50)
ix = torch.multinomial(topk_probs, 1) # select a token from top-k probabilities | is now (B, 1)
xcol = torch.gather(topk_indices, -1, ix) # gather the corresponding indices | (B, 1)
x = torch.cat((x, xcol), dim=-1) # append to the sequence
First, the x that we are providing is of the size (B, T) the batch (B) and the number of times (T) we need it. What we will be doing is to loop through each of the indices and produces new ones. So during each iteration, we are generating new columns into x.
Next, all of the operations are happening within the context of torch.no_grad(). We are basically telling PyTorch that it potentially doesn't have to prepare for .backward(), so it doesnt have to cache any of the tensors or anticipate backprop operation on any of the operations. Therefore saving time and space.
So we get the logits from the model logits = model(x), then we are taking just the last column, dropping off everything else logits = logits[:, -1, :] (Apparently we are being inefficient here. The logic is correct but we are just making a simple sampling loop). Then we are passing through the Softmax layer to get the probabilities probs = F.softmax(logits, dim=-1).
We are then taking the top k probabilities tokens, in our case the top 50. This is following what HF had done in their pipeline. Ultimately, we are ensuring the model is only taking the most probable tokens and not consider any of the rare ones. Therefore, we are ensuring that the model is efficient to the max and doesnt randomly get lost in generation - topk_probs, topk_indices = torch.topk(probs, 50, dim=-1) and ix = torch.multinomial(topk_probs, 1).
Finally, we are getting the new column xcol in xcol = torch.gather(topk_indices, -1, ix) and appending it to x in x = torch.cat((x, xcol), dim=-1). So, x now has the sequence of characters which we need to iterate through and print the output as we will do in the following code:
for i in range(num_return_sequences):
tokens = x[i, :max_length].toList()
decoded = enc.decode(tokens)
print(">", decoded)
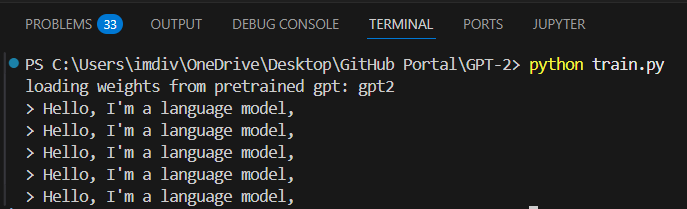
Now, we run the python script and see what our model generates!
Dubugging moment, yay! (part 2)¶
So, i had faced several issues which i would like to point out. I haven't updated them in this notebook (coz i want to revisit them) but its been updated in the main train.py file :)
Okay lets start,
CAUSE OF ISSUE: No output was generated by the model
ISSUE 1: Wrong loop condition
while x.size(1) > max_length: should be while x.size(1) < max_length:
ISSUE 2: Not updating x through the Transformer blocks
In GPT.forward i put:
for block in self.transformer.h:
block(x)
it should be:
for block in self.transformer.h:
x = block(x)
ISSUE 3: Typos in the math part of CasualSelfAttention
In CasualSelfAttention.forward i wrote attn = (q @ k.transpose[-2, -1]) * (1.0 / math.sqrt(k.size[-1])) but it should be attn = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))). So the loop kept crashing as it couldn't iterate.
ISSUE 4: Wrong dimension added to softmax
I wrote attn = F.softmax(attn, dim=1) instead of attn = F.softmax(attn, dim=-1).
ISSUE 5: I faced an error "AttributeError: 'ModuleDict' object has no attribute 'lm_head'"
So, in my forward, lm_head is not inside self.transformer — it's declared separately. Therefore,
logits = self.transformer.lm_head(x) should be logits = self.lm_head(x).
RESOLVED OUTPUT:

Milestone checkpoint!
- And boom! we have our output from the model!
- Everything we've done so far: Imported all the weights, initialised GPT2 (this is the exact openai gpt 2), they can generate sequences and they look sensible. We've obviously provided the weights of the model. The next task is to do this using random numbers and see if we can generate similar or better sequence of characters.