Section 2 - A¶
Let’s make it fast. GPUs, mixed precision, 1000ms¶
So in these next 2 sections (including this) we are going to be focusing on increasing the speed of our training. But thus time, its not just making the code more efficient but also understanding our hardware, what it offers and are we efficiently using it?.

So the above are processing speed capabilities of that GPU (A100 in sensei's case).
The general stuff which i felt were necessary to understand:
- tflops (teraflops) is some kind of speed.
- tflops: teraflops, flops: floating point operations (per second)
What we need to see are the specs from top to bottom i.e. how many tflops can be processed based on the datatype of our tensors.
So, in our case, right now, pytorch has its tensors of the type float32 by default (see screenshot below), so thats 19.5 tflops according to sensei's GPU specs. Now, our aim is to be able to utilize the GPU to a better extent right? therefore we will try to change the dtype into those which are lower in those table specs, inorder to get in more tflops for processing.
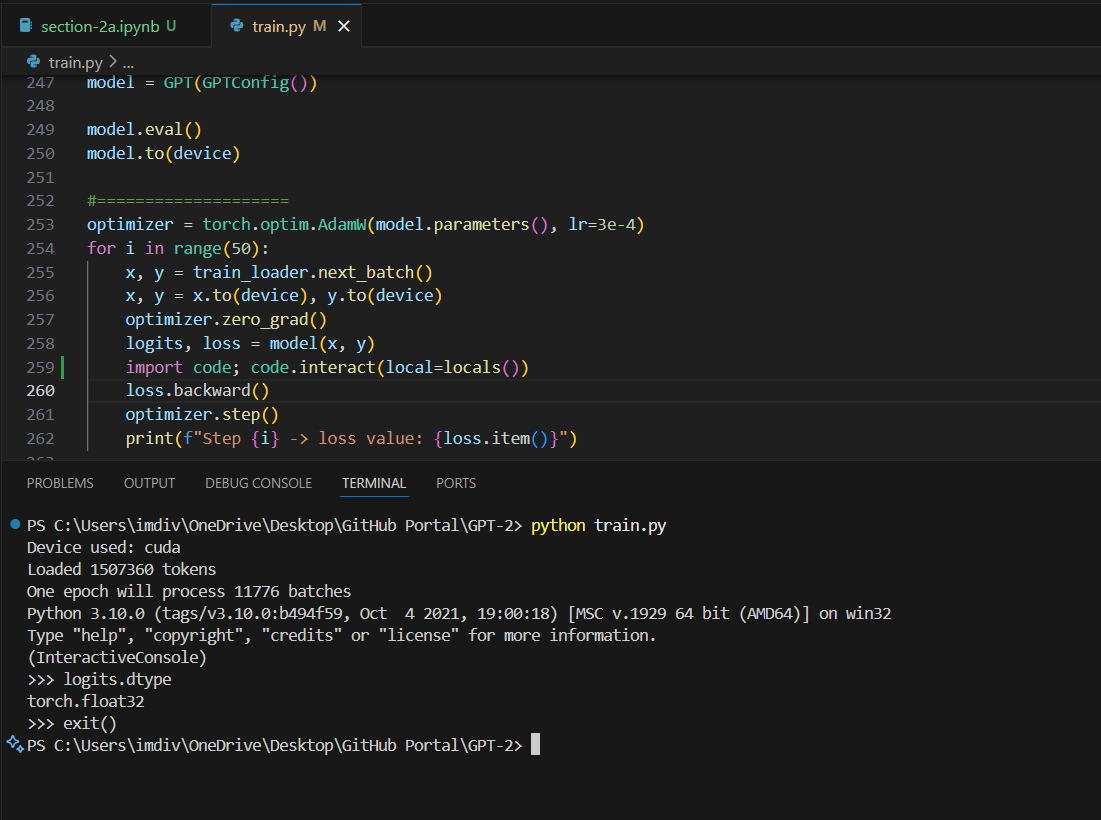
He experiments with two: tfloat32 (156 tflops) and bfloat16 (312 tflops) - This is exactly what is going to happen in the next two sections.
And why not INT8 which has like the most tflops processing? Apparently we use that duing inferencing and not training. And float is better so that we get a better match of the values duing Normal distributions (activations and weights) that occur duing training.
Also, why are we doing this and not just go ahead with the default dtype? It seems float32 is a little too high for a computational workload when it comes to deeplearning. Therefore we can make it lower, to smaller precision. But it is also important to note that not all hardwares/GPU can provide such precision, and thats where top expensive GPUs come in like A100 where as shown in the image can process even the highest i.e. FP64 (which apparently is quite useful for scientific computing applications and there they really need this).
Lastly, we also have to consider the memory and its bandwidth (the speed with which it processes it) while we are efficiently using this hardware.
Tensor Cores, timing the code, TF32 precision, 333ms (8000ms)¶
Tensor cores are basically like an instruction provided to the GPU architecture, where essentially all the computations that are happening internally in this transformer for instance, are all just matric multiplications.
In our case it will be mainly in the Linear layers, but ultimately the biggest matrix multiplication we have in this setup will be the classifier layer at the top, which is like the main one and almost handles the entire transformer arch that we are building (Go through that timestamp of the video if you want more information on it - He also explains how the bytes are processed by the hardware i.e. F32 externally, but interally its T32 etc and how prolly the only tradeoff would be the precision).
Timing the code is where we make some additions to our optimization loop as the following:
import time
train_loader = DataLoaderLite(B=2, T=1024)
#====================
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
for i in range(50):
t0 = time.time()
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
logits, loss = model(x, y)
#import code; code.interact(local=locals())
loss.backward()
optimizer.step()
# print(f"Step {i} -> loss value: {loss.item()}")
torch.cuda.synchronize()
t1 = time.time()
dt = (t1 - t0)*1000
print(f"step {i}, loss: {loss.item()}, dt: {dt:.2f}ms")
import sys; sys.exit(0)
#====================
Now, here we are using the time library. How using GPU works is that, the CPU basically allocate tasks to the GPU for it to run right. There will be cases where the CPU keeps allocating and without waiting for the GPU to finish it will call the .time() even though that task was not yet finished. Therefore we are timing our code by using torch.cuda.synchronize() to basically wait till the GPU's task is also complete.
After having made those chnages, we also updated our batch size and the sequence length. Sensei went ahead with train_loader = DataLoaderLite(B=16, T=1024) as his GPU can handle it. Batch size is what he chose, but the sequence length is the same as that of the OG GPT-2 architecture. Note that this before we go ahead and use the tflops modifications.
I went ahead and experimented with what my GPU can handle as well, starting with the time it took for (B=4, T=32) to what worked for me (B=2, T=1024).
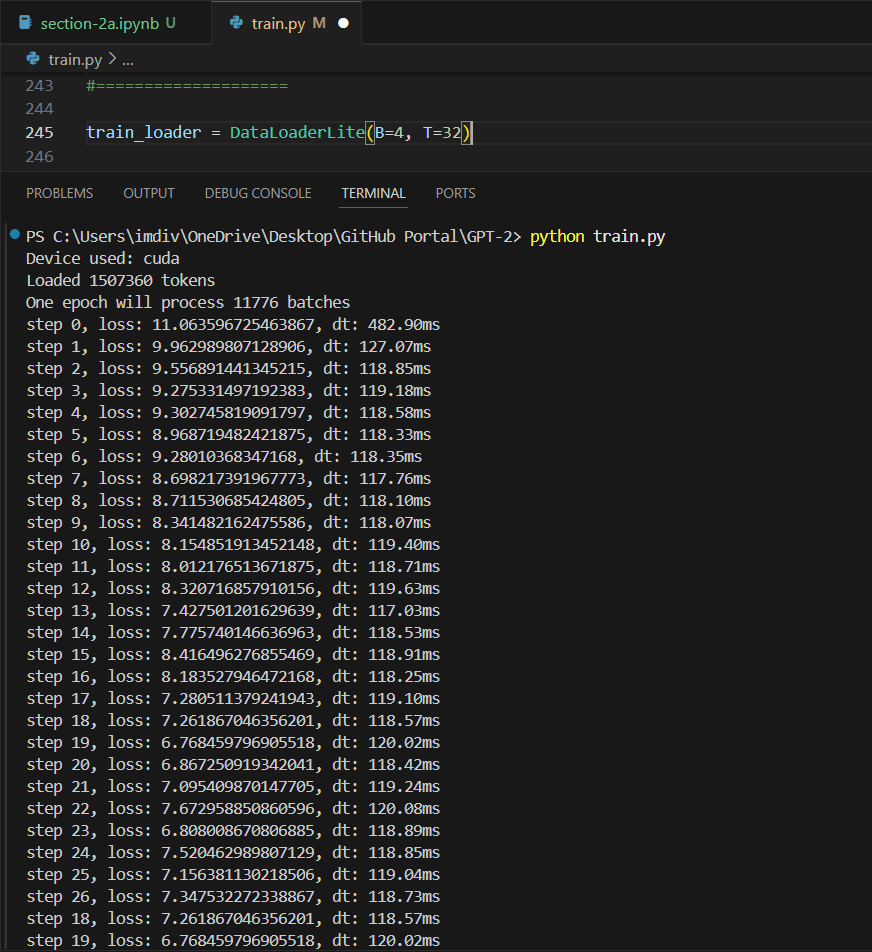
(Default dtype) B=4, T=32
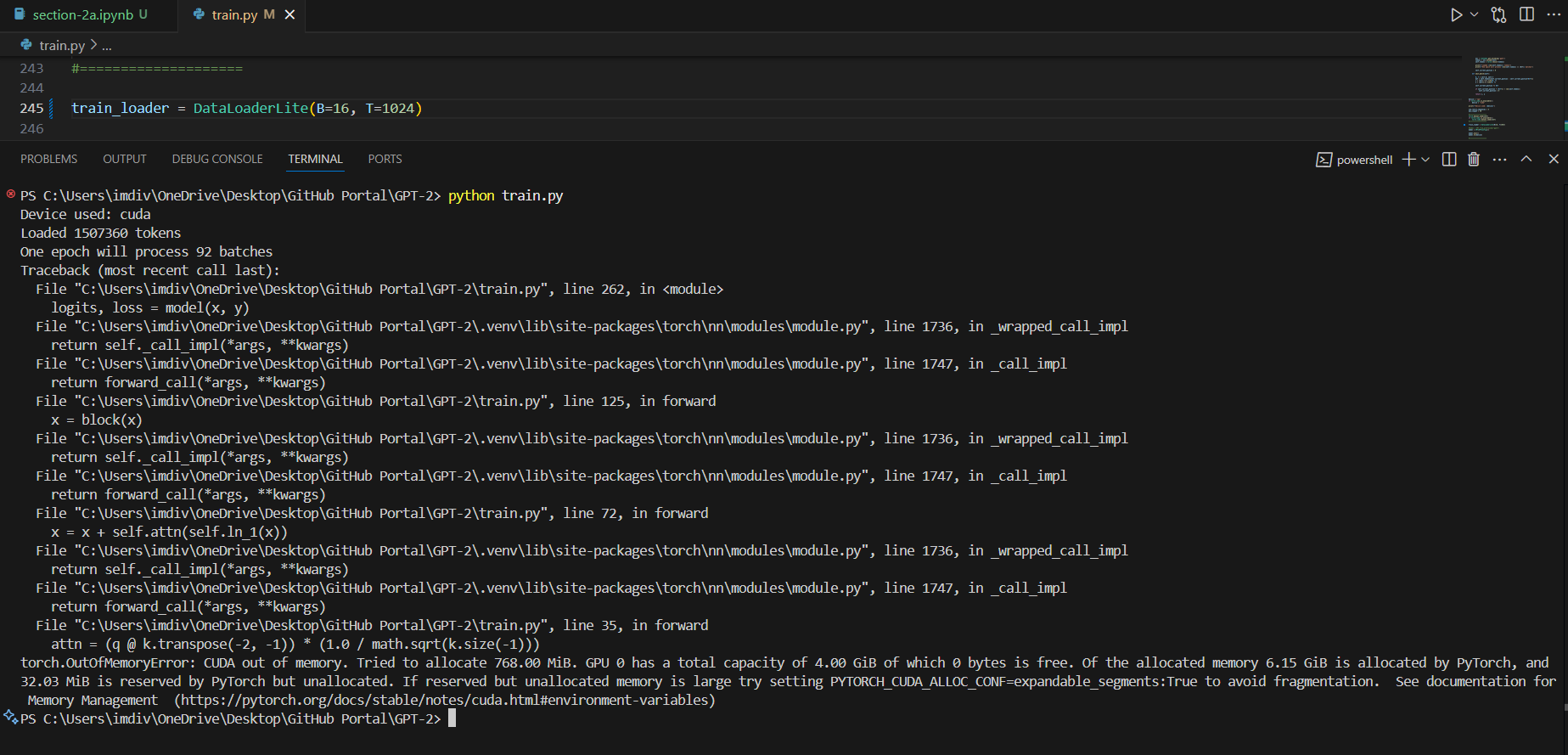
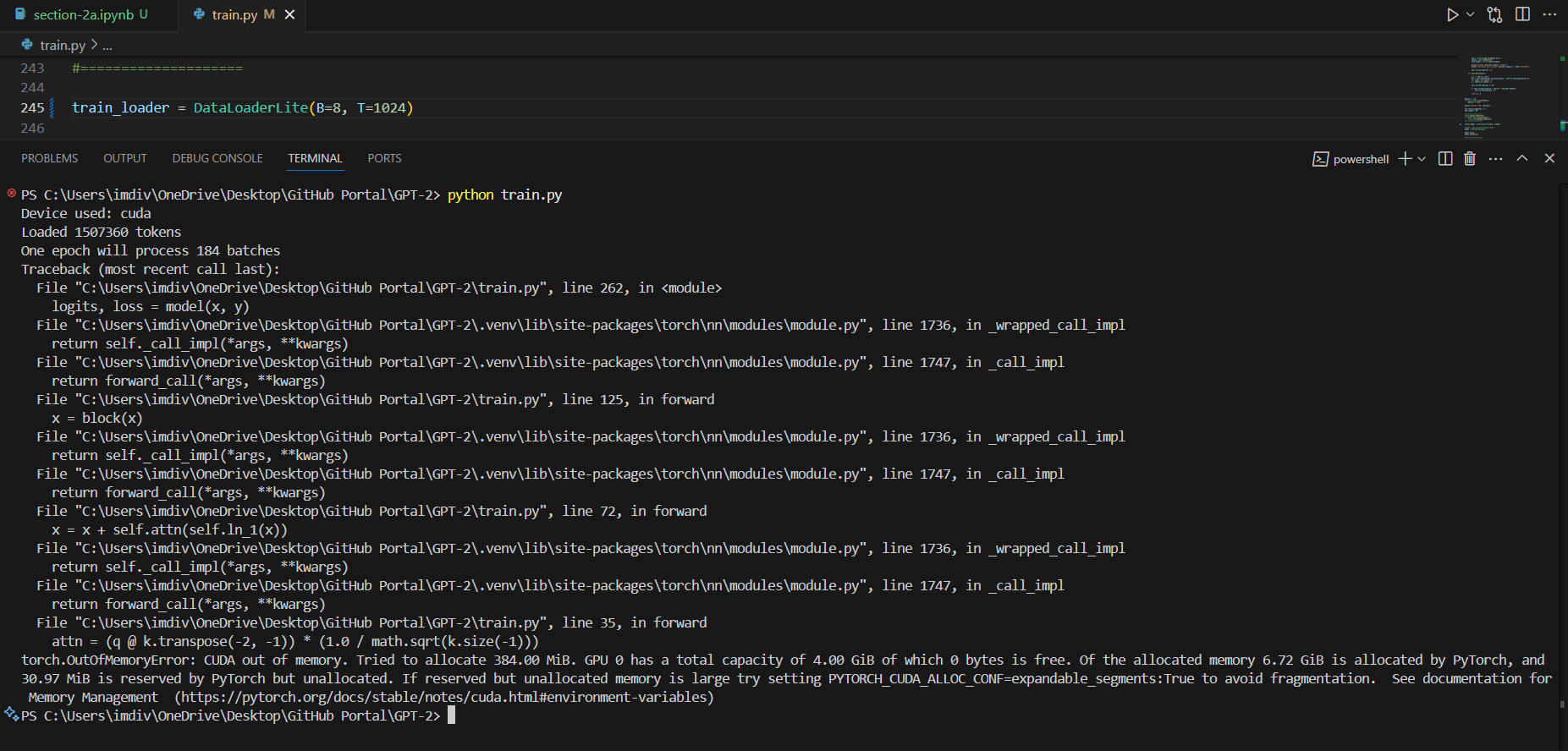
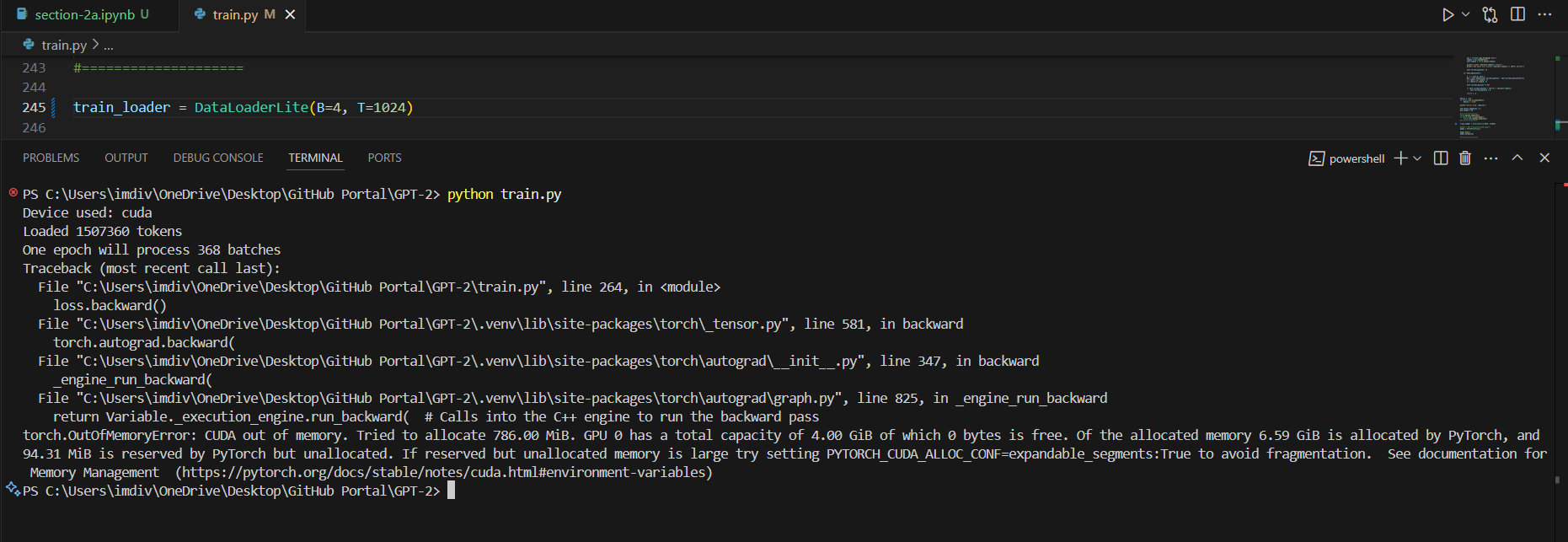
(Default dtype - CUDA OutOfMemory errors) B=16/8/4, T=1024
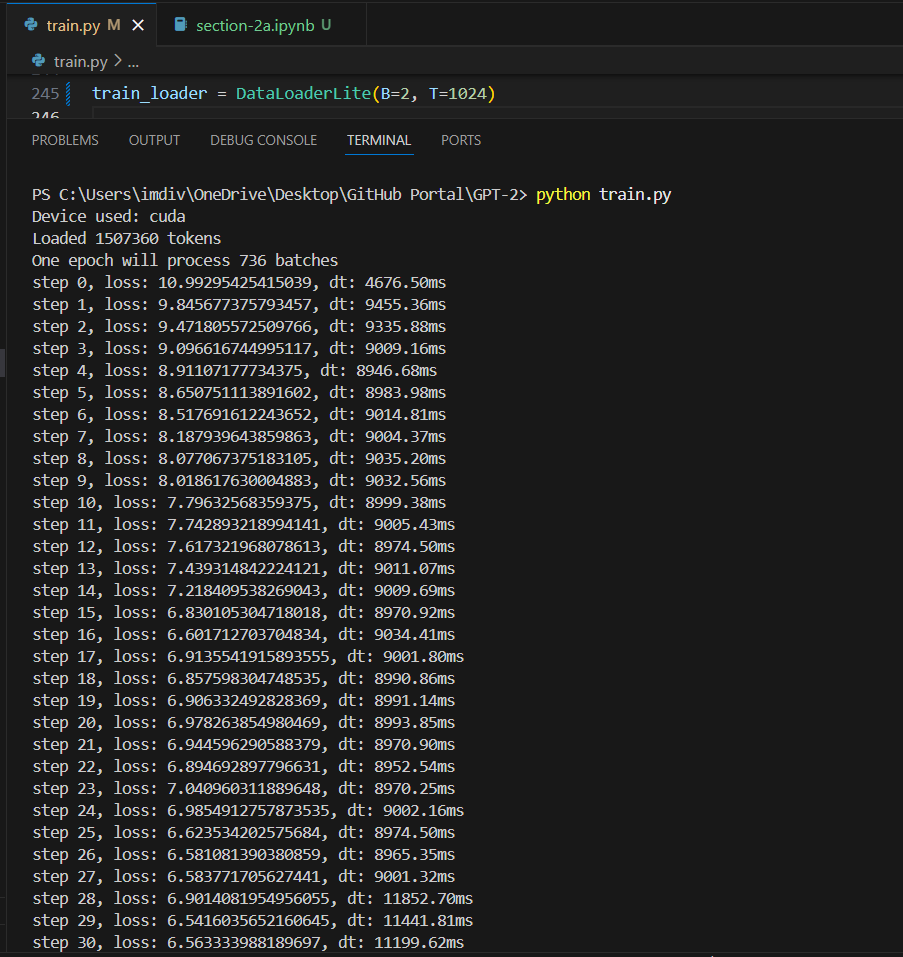
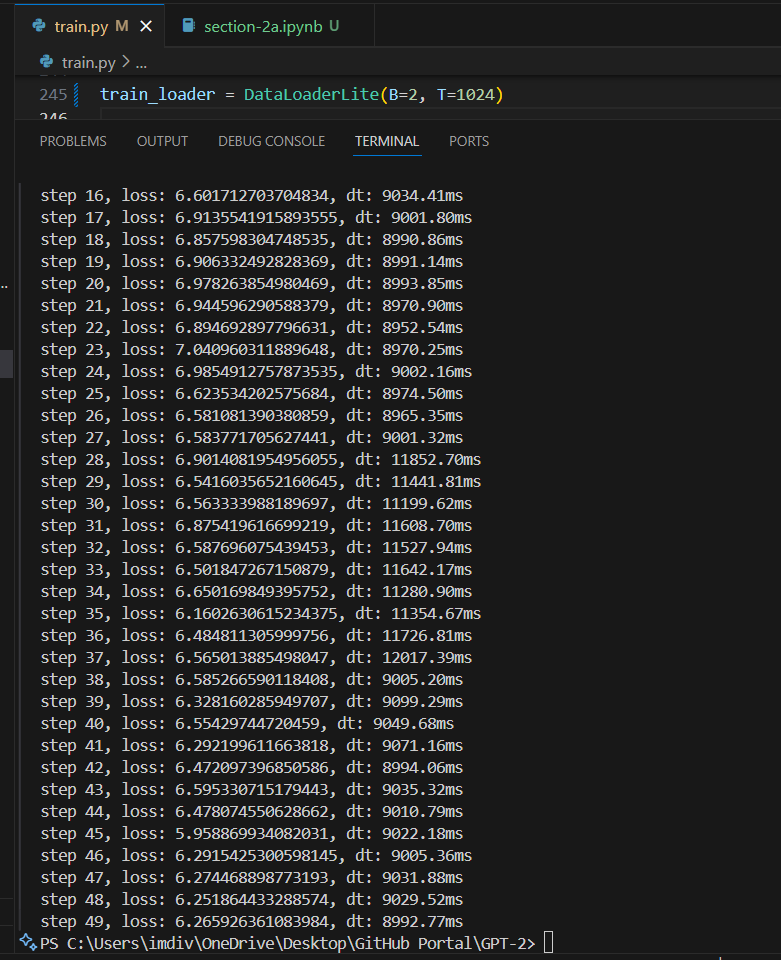
(Default dtype - what worked) B=2, T=1024
tf32 precision can be set in pytorch using torch.set_float32_matmul_precision('high'), the parameter "highest" is the default one which continues to use float32 itself.
So, i ran that, with also not being aware if my GPU can even support this, so i didnt see much of a difference, but it consistently ran at a >8000 and <9000 milliseconds, which i guess is ok?
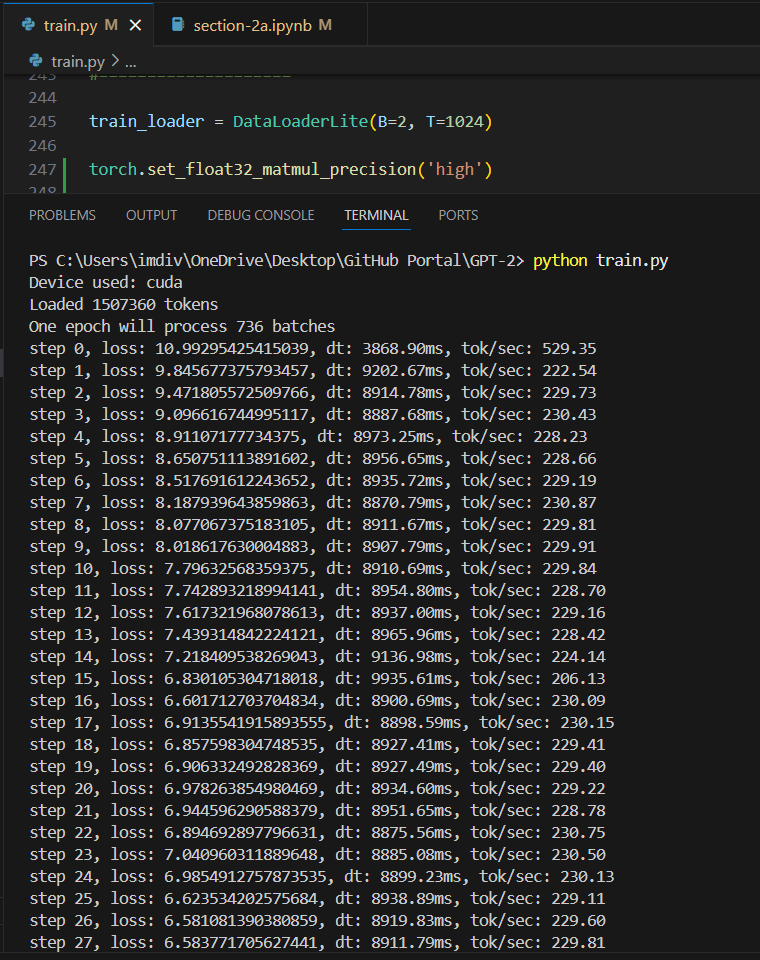
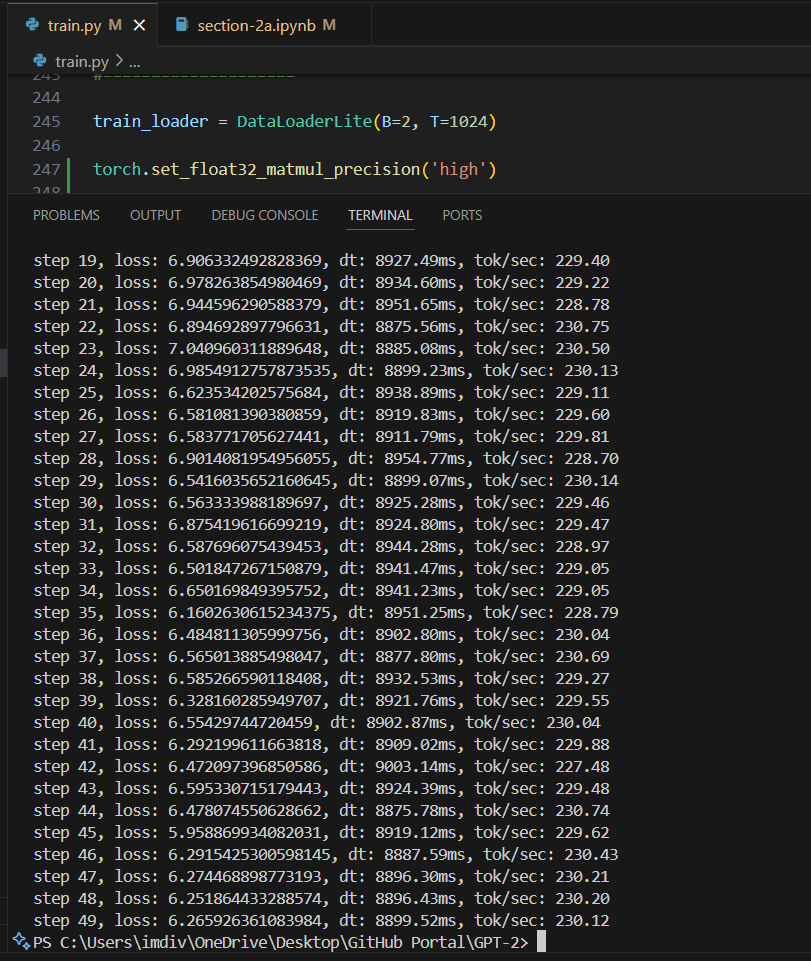
(TFloat 32 dtype) B=2, T=1024
float16, gradient scalers, bfloat16, 300ms (12000ms)¶
So we saw if we can improve the speed with tfloat32, but now we are about to reduce the precision even further by using bfloat16. Turnsout this is a more older version and the way to use this in pytorch is using autocast. So there are specific syntax to it i.e. which step during optimization can we actually use this (See these two links: Link 1 and Link 2), therefore we make the following addition to the code:
#====================
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
for i in range(50):
t0 = time.time()
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
with torch.autocast(device_type=device, dtype=torch.bfloat16): #here
logits, loss = model(x, y) #here
#import code; code.interact(local=locals())
loss.backward()
optimizer.step()
# print(f"Step {i} -> loss value: {loss.item()}")
torch.cuda.synchronize()
t1 = time.time()
dt = (t1 - t0)*1000
tokens_per_sec = (train_loader.B * train_loader.T) / (t1 - t0)
print(f"step {i}, loss: {loss.item()}, dt: {dt:.2f}ms, tok/sec: {tokens_per_sec:.2f}")
import sys; sys.exit(0)
#====================
The other thing is by reducing the precision we are compromising the accuracy of the output but increasing the speed of the training. But sensei is saying its a ok tradeoff as we can coverup for it by running the training step for longer time.
Next is, here only the logits will be in bfloat and the rest still in float32 as that is one limitation of autocast (so the normalization steps etc will sitll be in float32), the following snippet from the documentation shows that.

So i went ahead and ran the code with the above changes, and the results were quite... not as expected. It took the longest time we've tested so far, not sure what went wrong there but i will look into that or is it just my hardware limitation.
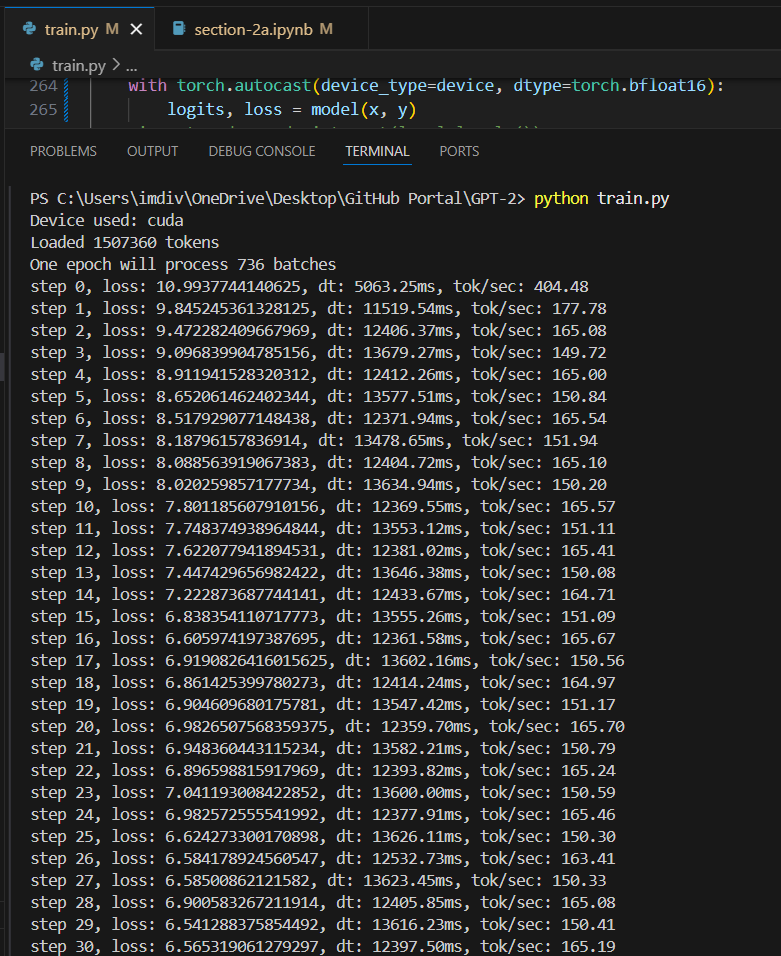
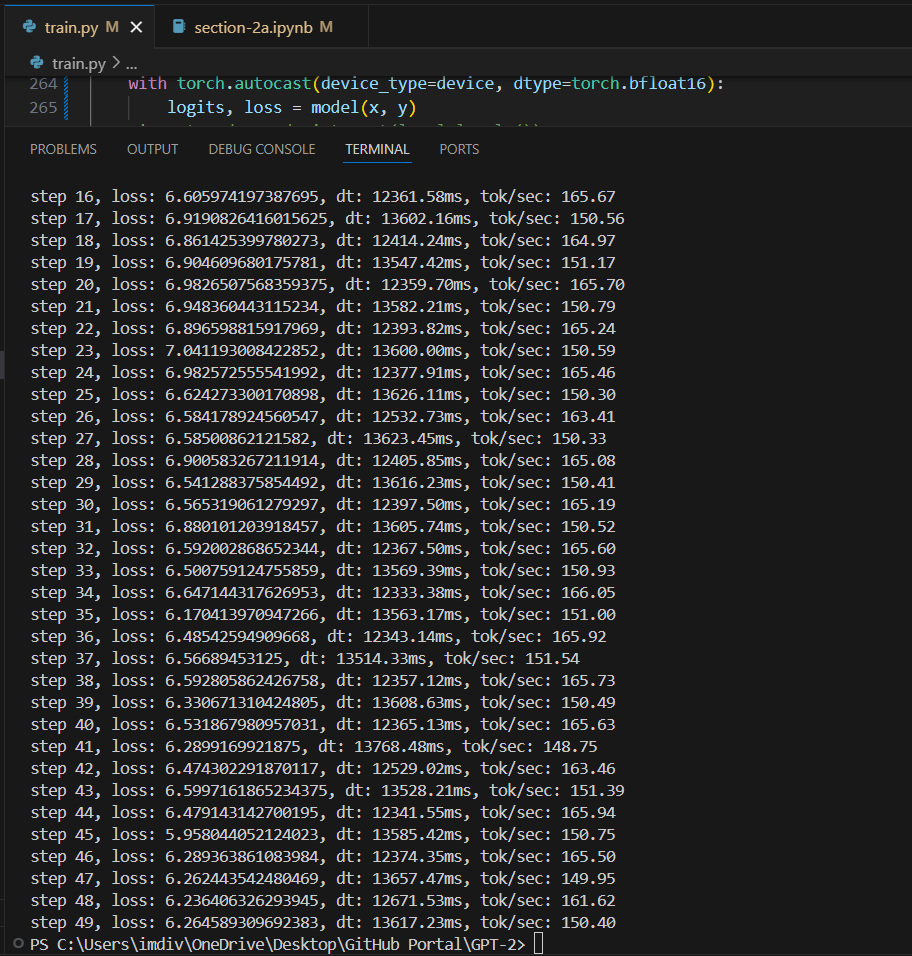
(BFloat 16 dtype) B=2, T=1024
There are still a lot more bottlenecks to our GPT2 implementation and we are just getting started. We'll go on to do further improvements so we will see how it goes! (I guess i will certainly have to rent a high power GPU at the end of this so lets go!)