DEEP DIVE INTO LLMs¶
Timeline: 19th - 23rd March, 2025
SECTION I: PRE-TRAINING¶
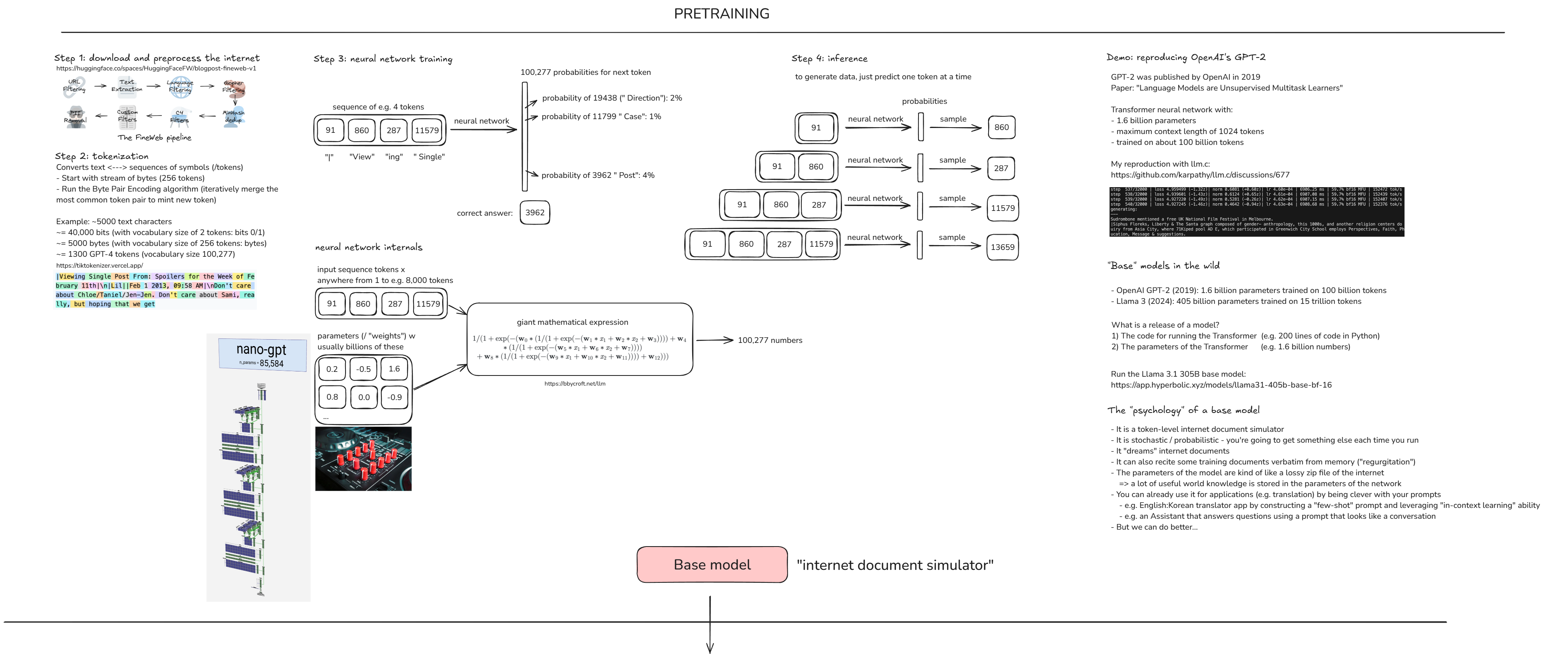
Pretraining data (internet)¶
(Fig. STEP 1) Hugging face site - FineWeb dataset.
Tokenization¶
(Fig. STEP 2) Website was useful to view tokenization and cl100k_base is what GPT-4 base model uses as its tokenizer.
Neural network I/O¶
(Fig. STEP 3 (i)) Neural network internals
(Fig. STEP 3 (ii)) The model architecture visualization site, pretty good interactive + detailed overview.
Inference¶
(Fig. STEP 4) Basically means, "To generate data, predict one token at a time". And this is what ChatGPT is essentially doing, it is inferencing, its generating next words and that is what we are seeing in the tool itself.
GPT-2: training and inference¶
(Fig. Demo)
- Timestamp: 31:09 very nice demo to see the internal processing of training the model and it inferencing the output (Will cover this in in my own GPT2 implementation as I do that lecture).
- Timestamp: 39:30 - 42:52 Loved this part, the best visual explanation of how everything looks in a large scale and in industry standard POV.
- Resource for renting Cloud computers with GPUs.
Llama 3.1 base model inference¶
-
(Fig. "Base" models in the wild) One point I liked here (which I wasn't aware of but was always curious on) is explaining the meaning of the model names, 'Instruct' meaning it is an assistant model. 'BASE' is of course the base model that is obtained after pretraining.
Resource for interacting with base models (paid).
Practical points on Base models:
- Also remember, this is not yet an assistant. It’s a token generator, so more of a 'Stochastic system'. So even if you ask a question for let's say recommendations, it will start to put out tokens and most of them maybe correct. But it is important to remember that in this model, more the frequency of certain information in the training data, the more likely it is to remember that and generate it. So this model, right now will mostly just generate texts it has the highest probability of remembering.
- There are also cases where 'Regurgitation' happens where the model ends of remembering EXACTLY what it learnt during its training, word by word. This is usually undesirable. This mainly happens because it might be the case where, that particular information had appeared or was trained in multiple epochs (because it is from a very reliable source with rich data, like Wikipedia), so the model ends up remembering it. Eg shown in video: Adding a line from Zebra article from Wikipedia, most of it is almost exactly the same, but at some point it will deviate and start to produce something random.
- Then comes the most famous case- 'Hallucination'. Where when the model is asked something it definitely wasn't trained on, then it just takes its best guess and starts to produce data. Eg. in video: 2024 presidential election as the data for llama3 was till the end of 2023 only.
- Another popular case where we implement 'Few shot prompt' where see the model's 'Context learning ability' in action. Eg in the video: You give a set of examples, like a word in English and its Japanese equivalent, finally you just give an English word and ask it to generate, and it will.
Pretraining to post-training¶
Here we come to the end of SECTION I, where we went through the 'PRETRAINING' stage and the output produced is the 'BASE MODEL' as we see in the diagram. Now, most of the computational heavy lifting is already done here so in this next stage it will be fairly less expensive to implement. And this stage is called 'POST-TRAINING'.
SECTION II: POST-TRAINING (Supervised Finetuning - SFT)¶

Post-training data (conversations)¶
-
(Fig. Conversations) We want to convert the base model to an actual assistant which can handle conversations. There are 3 examples which we can take:
- A General conversation, question and answering with follow ups
- A friendly assistant (based on the last message in the second block in the figure)
- An assistant with the capability to deny anything.
Now, we are not going to explicitly program the assistant using python or anything that. Because this is NN, we train this by providing datasets. So, the dataset will contain hundreds and thousands of conversations like the three examples mentioned above and more. Therefore you can say that the assistant is being "programmed by example".
In this stage of post-training, we take the base model obtained after pre-training, we chuck out the internet information dataset on which it was training on and swap it with these new conversations dataset and train it. The pre-training may take months, let's say in this example 3 months. Then the post-training would only take like 3 hours.
-
(Fig. Conversation Protocol / Format) The questions now are: Where are these conversations? How do we represent them? How do we get the model to see conversations instead of just raw texts? What are the outcomes of this kind of training? What do you get (in like a psychological sense) when we talk about the model?
The tokenization of the conversation. Different LLMs have different methods. When we look at the one GPT-4o uses we have
|im_start|,|im_sep|and|im_end|, theimstands forimaginary monologue. For example, the first box conversation in the diagram would roughly convert to 1D list of 50 tokens as seen in the diagram. Also, thoseimlabels will be represented as "special tokens" so you will see that they will all have their similar respective values, therefore useful for labelling, telling the model what it needs to focus on.The outcome of this is such that, next time while training, lets say at OpenAI. They would just leave the last answering part blank, like |im_start|assistant:|im_sep| ____` and this is where the LLM takes over and starts predicting the next possible tokens (like how we see in Step 4 during pre-training).
-
(Fig. Conversation Datasets) Introduction to the 'Training language models to follow instructions with human feedback' :
- Human labellers were involved, examples also shown in the paper.
- The labelling instructions provided to the human labellers- be Helpful, Truthful and Harmless (Normally the instructions are very long, detailed and heavy, so obviously professionals are made to work on this).
- Sample open source dataset which followed the similar above pattern of providing instructions to the people on the internet and they produced the conversations forming the datasets, all properly labelled.
Naturally, we cannot cover every possible conversation a user may have, but as long as we have enough concrete examples, the model will take on that persona and will know what kind of answer the user will need. Therefore also taking on the
Helpful, Truthful and Harmlessassistant persona.In this day and age, we obviously don’t need humans to do this, naturally we have LLMs that help us perform this itself.
Resources: UltraChat, Visual diagram of categories of questions asked.
-
(Love this part by the way) Now we know how ChatGPT is actually producing these outputs or what are we actually taking to in ChatGPT. Its definitely not some "magical AI", Ultimately its from these labelled datasets which the labellers make. So its like almost having a simulation of those specialized labellers (educated experts on coding, cyber security etc.) we are having the conversation with real time. So its not really a "magic output".
So next time you query something on ChatGPT, lets say
Top 5 landmarks in Indiaand it provides a list of answers. There is a high probability that if that same question was present in the dataset provided by the labellers, the model will just directly simulate that response. If not, then it’s a more 'emergent' answer which the model processes based on what will be the most likely set of locations to recommend based on what people like, visiting frequency etc.
Hallucinations, tool use, knowledge/working memory¶
-
(Fig. Hallucinations) Naturally, there will be effects of the above training pipeline that we saw (the emerging cognitive effects as sensei said), the most popular one is ofcourse- Hallucinations. We've seen plenty of examples on that. Again the best way to probably explain this is, the traditional model doesn't have access to the internet, so it doesn't know. It just has the probabilities of tokens that it has and it just samples it from them.
Mitigation #1
- We see how Meta solved this in their Llama3 open source model. In their paper, labelled under the section 'Factuality' what they did is that: if there is something that the model doesn't know, then they take that and during training again, for that question they label the correct answer for that as "the model doesn’t know". So that actually worked (it does sound simple in principle lol).
- Now keeping that above principle in mind, imagine a system of LLMs doing this: LLM1 produces Q&A for a set of data -> Take just the Q and ask it to a LLM2 -> The LLM2 produces the A and is sent to LLM1 for checking/verifications -> If it is correct then LLM2 knows and is all good, else LLM2 should say it doesn't know.
- Therefore we interrogate the model LLM2 multiple times to see the answers it generates and compare it with LLM1 to check. If its wrong, then we go and label for that question in LLM2 to say that - the correct answer for that question is "I don't know".
Mitigation #2
- Using Tools - One of the tools is Web search so, Allow the model to Search! (Just like how humans would do lol). So we can introduce new tokens like
<SEARCH_START>and<SEARCH_END>, so when this is encountered, the model will pause the generation, it will consider the text between those 2 labels, copy paste it to bing/google search and then the correct answers are then passed to the model's context window. Then it's from that the data is taken and passed on as a response. So the context window is like a active working directory which acts a source of memory for the model from which it recollects data, tokenises them and produces the answer. - So the context window already has information on which it was trained on. Just that now we have these tools to function, where they search and collect more correct and relevant data and update the context window/add to it, which the model will reference from.
- Now, how does it know it needs to use search? Again we provide examples to it during training. Once we show the model enough examples of data on when, how and where it needs to do search, it gets a pretty good intuition of it and just performs the task. So all you have to do is just teach it :)
- Timestamp: 1:37:16 to 1:38:28 where we see that happening in ChatGPT. Just watch that clip if you want a better visual understanding of the above points.
-
(Fig. "Vague recollection" vs. "Working memory") Knowledge in the parameters == Vague recollection (e.g. of something you read 1 month ago)
Knowledge in the tokens of the context window == Working memory (eg. you provide the paragraph context to the model, so the model has direct access to the information and doesn't have to actively recollect it. This provides better answers. Even as humans we give better answers if we had the immediate context to the info VS something we read months ago.
Knowledge of self¶
-
(Fig. Knowledge to self) This part of the video was kind of like a slap in the face for me lol, I have done this countless of times to various different chatbots that I've encountered thinking I was the smart one. But it turns out, it was a really dumb thing to do lol (always learning something new eh).
This case explains the time when the user asks "Who built you?" or "What do you use". Now, if we think about everything we have learned so far in this lecture, if it is something the model hasn't been trained on, it will most probably or if not, WILL hallucinateand will say "by OpenAI!" as that’s what most of the training data may have contained (LMAO CRYING). But if it is like a case in this open source model where it has been specifically instructed to answer that question, then it will take from its knowledge and answer the question based on what it was trained on.
Or we can also add 'System Message' as we see now, so for each conversation context window, the system message is added as invisible tokens :)
Models need tokens to think¶
-
(Fig. recall: next token probabilities) This part is probably the next most favorite part of the lecture for me.
Here, we are given two sample response from the model and are asked to choose the better one. Naturally, what i did was to see 'HOW I WOULD SOLVE' this problem and concluded that the second option (right) was better. Reason: I broke it down the same way in my head (logic wise only).
Turns out there is a more computational way to explain this:
- Now, look at the diagram. While thinking of a response you can image the model generating the token from left to right. And for the token which will contain the answer is where the heavy amount of computation will happen.
- We should also note that, in a model such as the one we see in the image, there aren't many layers for computation (the attention layers etc.). So there is just too much computation happening in the forward pass in that one token and that is not good.
- Therefore it is important that the model breaks down the process into various steps before concluding to the answer. This way we are not stressing all the load on one token, but taking our time to reach to the answer (therefore also spreading out the computational resources, so not much strain on the forward pass of the network)
What's even more beautiful is that we can also see this during the tokenization process in that site as well:
- Place the first response and see the token breakdown. After
'The' ' answer' 'is' '_'the token is left for the answer and it is that one token where the model is putting way too much computational load. And once that is done, the task is considered to be over and the rest of the message that you see is just something that it makes up! - Similarly, if you see the token breakdown of the second response. You would see that it is "spreading out it's computation" until the final answer is reached the end only.
- This way we can conclude and mark that the second answer is significantly better and correct. In fact the first answer is terrible and is bad for the model, as that indicates that it hasn't been labelled properly during training (as we end up teaching the model to do the entire computation in a single token which is really bad). So, seeing that your model actually breaks down its task to multiple token before concluding to the final answer is actually a good sign.
Now, we don't really have to worry about this as people at OpenAI (taking ChatGPT as an example) have labelers who actually worry about these things and take special care that the right answer generation is considered. So the next time you see ChatGPT break down a math problem into multiple steps before reaching to the conclusion (even if it is a simple one), remember that the model is doing that for itself and not for you :)
We've also had cases where we specifically ask the model to calculate the answer in one go. If it is simple, it will give you the correct one. But if it is a harder one, then you would see that it fails to give the correct answer. But it will find it easier and provide the correct answer once it breaks down the process (You can see this example in the video from 1:54:03 to 1:55:50. I have also faced this in real life during work and that explains a lot haha)
Note: Turns out, even the process of allowing the model to break down the code is kind of risky as it itself is thinking of the answer (like how we do mental calculations) which is not reliable in most cases. So here, we can instruct it to use a tool like
Use code, so what this will do is it will use the special tokens to call a python interpreter. So this can be more reliable as the solution is programmatically generated (there is also no additional tokens for it, the code itself is generated, passed to the interpreter and answer is generated). So don't fully trust the output when it does it using memory, use tools whenever possible. -
(Fig. Models can't count) Another example of relying on tools while the model performs computation. Sensei uses the example of counting the dots. Now, models aren't good at counting (we've also seen that in the way it splits the tokens). But we know its good at 'copy pasting'. So when i ask it to "use code", it will correctly copy the dots given to it and provide it to the interpreter. So this way we have also broken down the task which is easier for the model to perform.
Final summary for this section: So we can see how models actually need token to think (phew, this took me ages to cover lol, but so worth it).
Tokenization revisited: models struggle with spelling¶
(Fig. Models are not good with spelling)
- Models don't see characters, they see tokens.
- Models are not good at counting.
The above two points are so massively important as we've seen simple tasks where models fail to perform like "Print every 3rd character from this word" or more famously "How many r's are there in strawberry". The root cause of that is tokenization, therefore those two points.
So here is where we come back to tokenization again. Incase of those example queries, the model interprets them differently as it sees them as tokens and on top of that if you ask it to count, we are basically asking it to do two of the most obvious tasks it is bad at.
Thoughts
This reminds me of the famous LLM lecture video from Stanford which i watched a couple of months back (while i was still in the early stages of makemore series) where during the first half, the lecturer was asked something and he said "in those cases is where we will see that TOKENIZATION itself is the main issue". It struck me a little that time as i thought tokenization was brilliant as the model is breaking down its task. But now i see what he meant there :) -Also yes I haven't finished that lecture yet lol, i should actually.
Jagged intelligence¶
You can watch the timestamp for this here, But mainly its to show some headscratcher situations with the model. The main takeaway is this- See it as a stochastic system, you can just rely on it as a tool and not just "let it rip".
SECTION III: POST-TRAINING (Reinforcement Learning - RL)¶

Supervised finetuning to reinforcement learning¶
Everything we've seen so far are the various stages of building a LLM. Usually in large companies (like OpenAI), each of the above stage have their own respective teams doing that work. And RL is considered as the final stage of this.
To get an intuition of what this is, we see the example of a textbook which we used to learn from in school- The theory is the Pretraining, the Solved examples are the Supervised finetuning and the problem questions which we need to solve is Reinforcement learning (The question is there, the final answer may also be provided, but its the process of getting there/how we solve it is how we learn).
Reinforcement learning¶
"What is easy or hard for us as humans/human labelers is different than what's easy/hard for models/LLMs, as they have different conditions. The token sequences are like a whole different challenge for it".
The process usually goes like:
- We generated 15 solutions.
- Only 4 of them got the right answer.
- Take the top solution (each right and short).
- Train on it.
- Repeat many, many times.
So RL is where we really get dialed-in. We really discover the solutions that work for the model, we find the right answers, we encourage them and the model just gets better over time.
DeepSeek-R1¶
Okay so, it is important to know that RL is something that has emerged very recently in the industry. Step 1 & 2 have been around for a while and companies like OpenAI have been working on this internally. But it was the DeepSeek paper that had publicly put it out and had also implemented it.
One of the most famous phenomenon you can say, that was introduced in this paper was the "aha moment" where the model is just rethinking by itself as it looks into the approach. So if a problem is provided, it looks into it with different perspectives, takes analogies and thinks internally in all the possible ways. And the reason this is incredible is because you cannot hardcode all of these. So this does show a huge step taken into the process of RL. Also, it is important to know that, this process consumes A LOT and I mean A LOT of tokens. So naturally you will see the response improving as more tokens is utilized.
Read these snippets from the paper to have a better explanation: Explanation and Example.
There are a few ways that you can run these state of the art models where it is already hosted for you: Hugging Face inference playgroundor Together AI.
One interesting point sensei has mentioned here while comparing the OpenAI's o1 models and DeepSeek, is that OpenAI chooses not to show the entire Chain of Thought (CoT) under the fear of "distillation risk" where someone could come and just imitate the reasoning steps of the model and almost recreate its performance (in terms of its performance settings), therefore they cut it short and don't show all of it's thinking texts.
Reinforcement learning from human feedback (RLHF)¶
RL is fairly under grasp when we are using it in a "verifiable domain" like solving a math equation where we know what the final answer is. Now, in cases of "un-verifiable domain" like telling jokes, there is no fixed answer so how do we train the model? That's where RL with Human Feedback comes in.
We get humans to evaluate a good chunk of data -> Train a whole different NN on it -> Use that Model produced to evaluate the responses and gives its scores.
So the RLHF approach is something like:
- STEP 1: Take 1,000 prompts, get 5 rollouts, order them from best to worst (cost: 5,000 scores from humans)
- STEP 2: Train a neural net simulator of human preferences ("reward model")
- STEP 3: Run RL as usual, but using the simulator instead of actual humans
Lastly, it is important to note that we cannot rely on RLHF completely, we need to peak its training at one point and then just crop it. If we allow it to grow after that, then it will just a way to "game" to model it is evaluating and the final outputs rated will almost be nonsensical.
It's best covered by sensei in these points-
UPSIDES:
- We can run RL, in arbitrary domains! (even the unverifiable ones)
- This (empirically) improves the performance of the model, possibly due to the "discriminator - generator gap".
- In many cases, it is much easier to discriminate than to generate. E.g. "Write a poem" vs. "Which of these 5 poems is best?"
DOWNSIDES:
-
We are doing RL with respect to a lossy simulation of humans. It might be misleading!
-
Even more subtle: RL discovers ways to "game" the model.
-
It discovers "adversarial examples" of the reward model. E.g. after 1,000 updates, the top joke about pelicans is not the banger you want, but something totally non-sensical like "the the the the the the the the".
SECTION IV: CONCLUSIONS¶
Grand summary¶
I encourage you to just watch this part of the grand summary once you've read the notes and just want to do a quick refresh of your knowledge. Start from here.
Ultimately, we've learnt the 3 main stages:
- Stage 1: Knowledge Acquisition of the internet.
- Stage 2: Is where the personality comes in.
- Stage 3: Perfecting thinking process and improving the problem solving.
Lecture resources¶
- Click here to view complete lecture drawing board image.
- Link to video: Watch here
- Download full drawing board here
- Import and view the above drawing board on Excalidraw
{kind=link}
Phew, that was one long lecture. Took me days to cover but it was truly refreshing. As he said again, very existing field to be in at a time like this. See you on the next one, Happy learning!