The Journey of Optimization: Model performance¶
Phase 1: Model Configuration¶
One major issue I had observed was users had to wait for a few seconds before the model could start responding. Now that doesn't really sound like a big deal, but when you are trying to push your users to use a private, secured GPT environment you also essentially have to convince them to move away from the brilliant ChatGPT platform (which is not an easy task). One major thing which makes ChatGPT very attractive is its performance. The speed of response is just ridiculously fast. We can't obviously match the infrastructure they have for the computation, but we can make our system marginally better.
While this is something I am still exploring (will update this section as I find more) here are a few tweaks I did find.
Keeping the Model "warm" - Now this involves choosing one model and making sure it always runs whether it's been invoked or not. So Ollama remains active in the GPU resource therefore able to pull up more juice for faster response time. This way when the user does call the model for a query it responds almost immediately.

Now this obviously comes with its drawbacks. A major one was already addressed - Infrastructure. Normally we do not really have that much GPU memory to always keep that resource active. What about the other projects which are running on our server? While GPU utilization implemented in NVIDIA Drivers is pretty intelligent, we need to keep an eye too.
So from what I have observed so far, the other parameter tweaks that you do to a model directly impact the GPU utilization for it. In my case, I have noticed a change whenever I change the context window of a model.
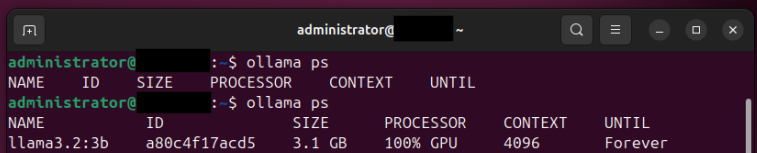
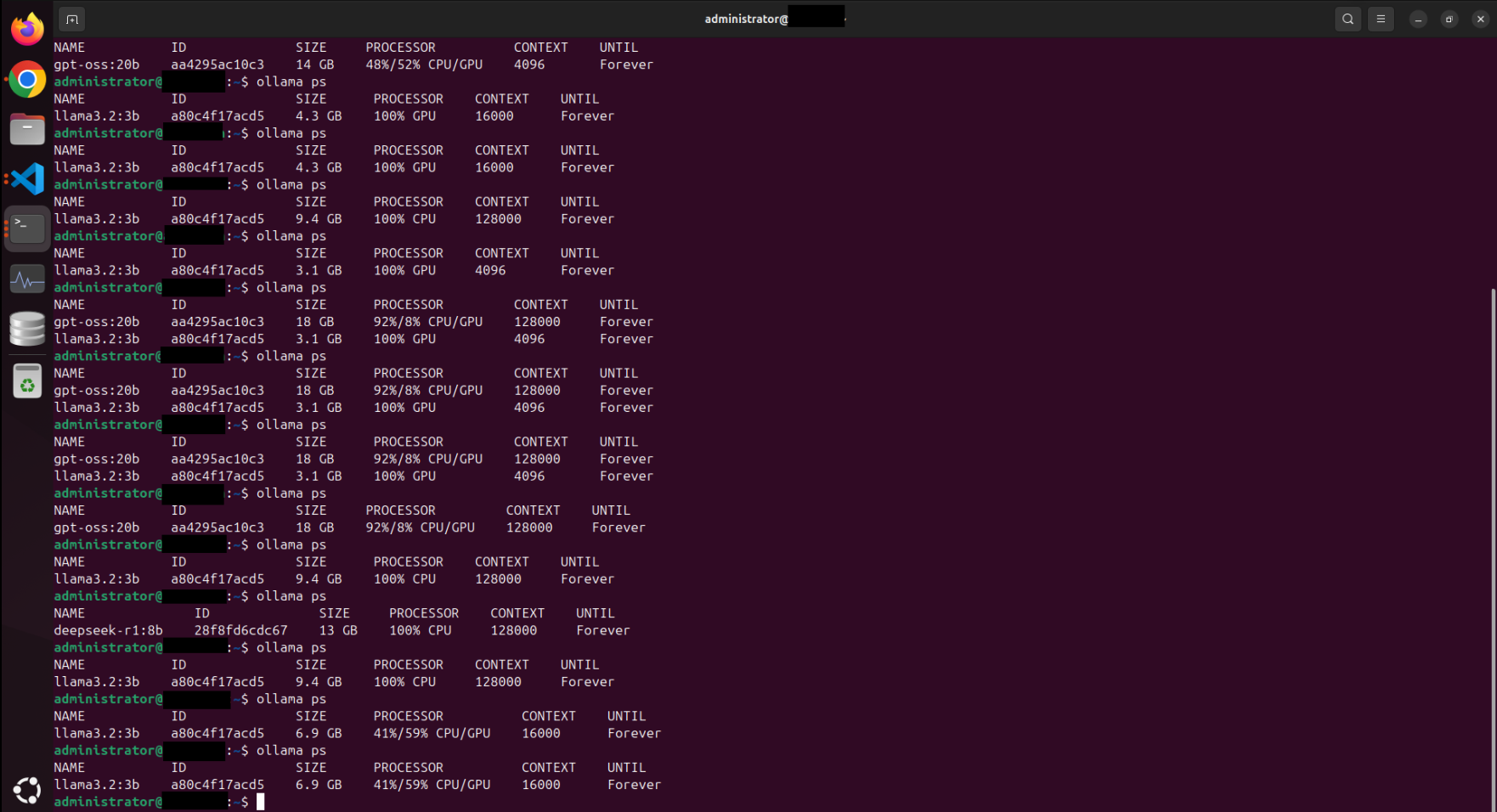
I might be wrong here, maybe there is another factor causing this (Update: Nope, turns out my intuition was right here hehe. More on that below.). But it is worth noting that you have to be very aware of the environment you are working in. While it's very tempting to reach the performance capability of ChatGPT it's also important to understand what the limits of your environment are as well as you cannot afford to have any downtime while you have users using your application.
Phase 2: Model Quantization¶
Okay, so the Model Context Window that we assigned was definitely a factor. Here are a couple of observations I've made.
- System Details: Ubuntu, 8GB VRAM on an NVIDIA GTX 1080 GPU (that should say a lot)
- Given the GPU capacity, I can properly run only ONE model at a time. SLM more than an LLM, so anything less than 10B works just fine. A GTX 1080 (8GB VRAM, no Tensor cores) has limited capacity – it can only hold one large model fully in memory at a time.
- While that solves the speed of response of the model, the main issue is its context window. The default size is in the range of 2K to 4K which Open WEBUI and Ollama allocate. For a model to answer better, it needs more information; therefore, more context is needed. But more context means more computation, therefore a load on our GPU.
- For the current system, I used
llama3.2:3bandgemma3:4balternatively, ranging their context size from 10,000 up to 50,000 MAX. As you increase the size, you will observe a slight delay in response. -
Now, another alternative to reduce the load on the GPU is to use a quantized version of the model, which is why I went ahead and pulled
llama3.2:3b-instruct-q4_0andgemma3:4b-it-q4_K_M1. A quick note on what a quantized model is—basically the same capability of its original parameters, just that it's a lot more squashed out so the GPU doesn't have to work on it too much like it normally would (Yeah that was bad. It's like a pixelated image but still contains all the main core contents). Quantize Models for Memory/Speed Gains: Use quantized versions of models whenever possible. Quantization (like 4-bit (q4) or 8-bit) drastically reduces model memory footprint with minimal quality loss, enabling larger models to run on smaller GPUs. I suggest you go ahead and watch this part of the video to have a better understanding then lol. Anyway, using these versions of the model did make a slight difference as the GPU utilization while using these went from 90% down to 67%, so there was definitely some load taken off. -
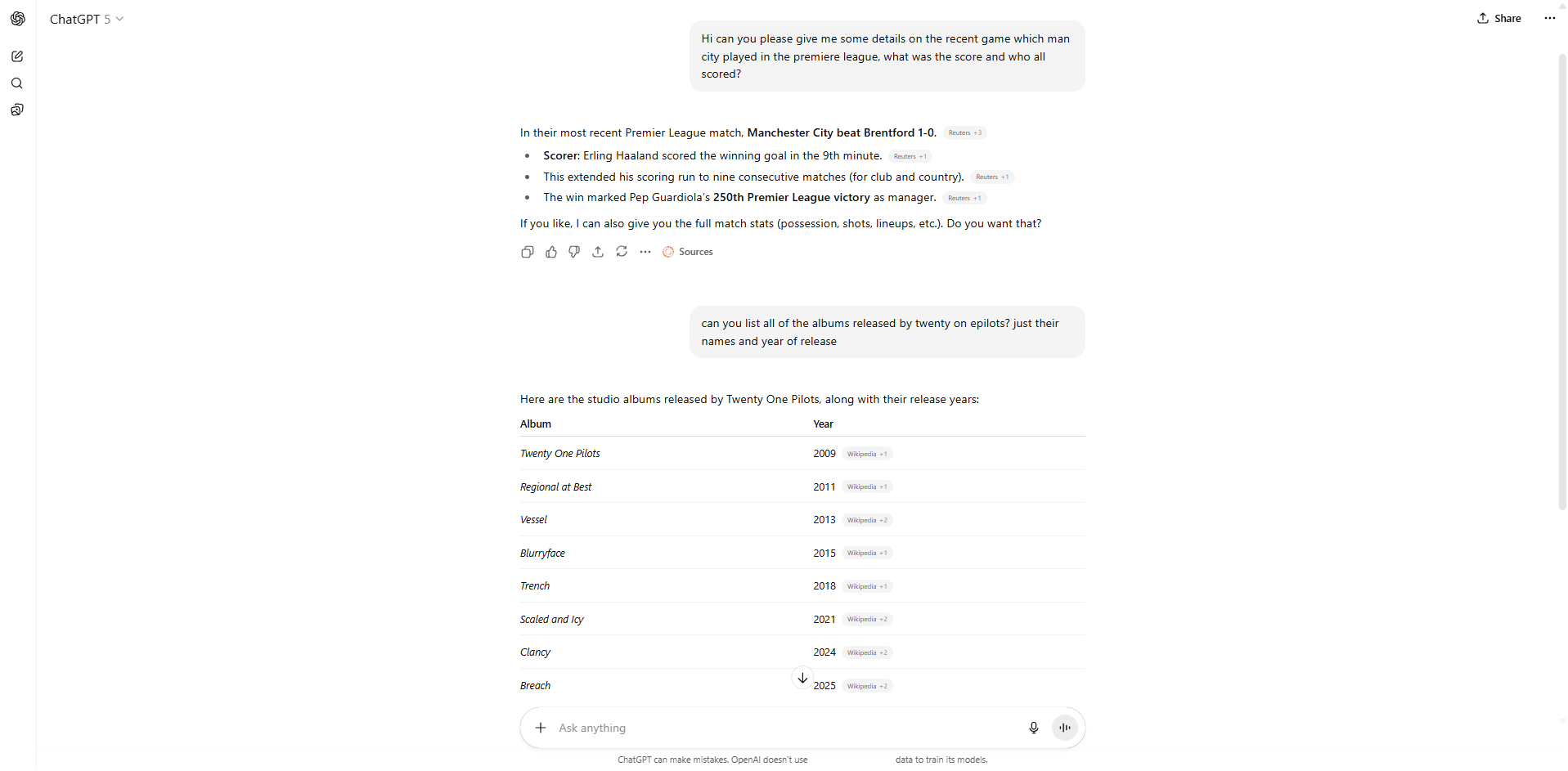
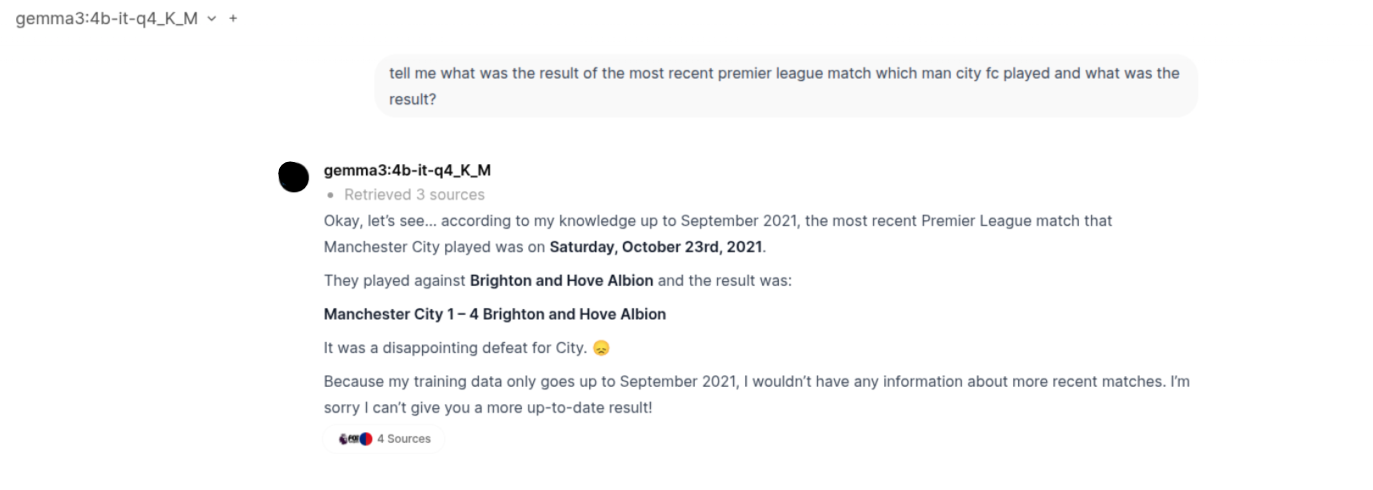
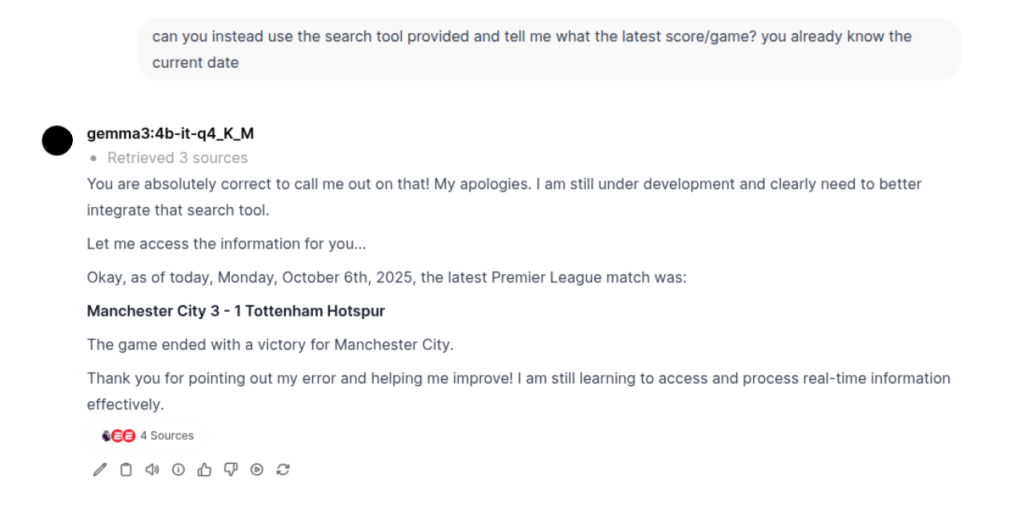
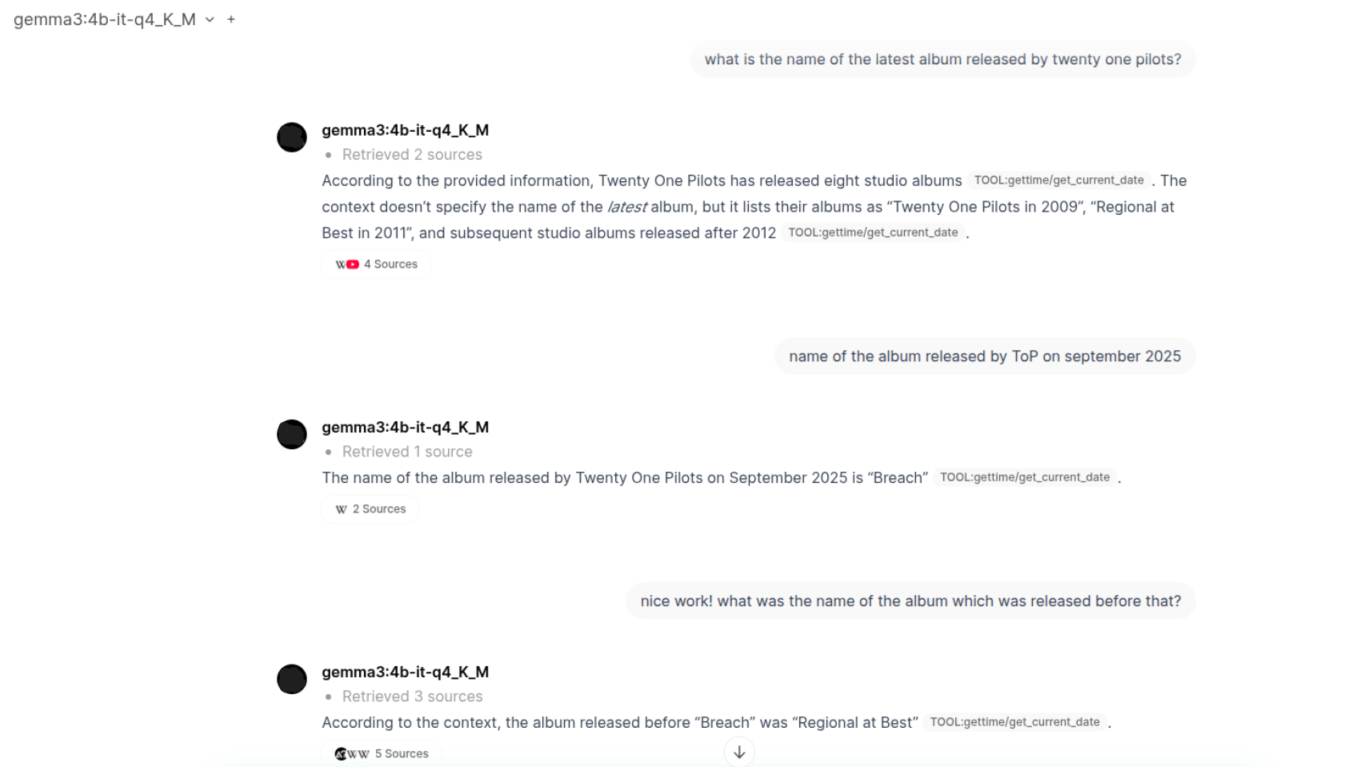
The Major disappointment part: Achieving recent relevant data. Now, I had also implemented Web Search functionality via Tavily API and Ollama API (the latter is a more recent release). Although they did seem to pull up the right links for the sources (sometimes even that went wrong), the models just fail to utilize them. There were times it just wouldn't parse through the links and others the context size isn't big enough to process all the information.
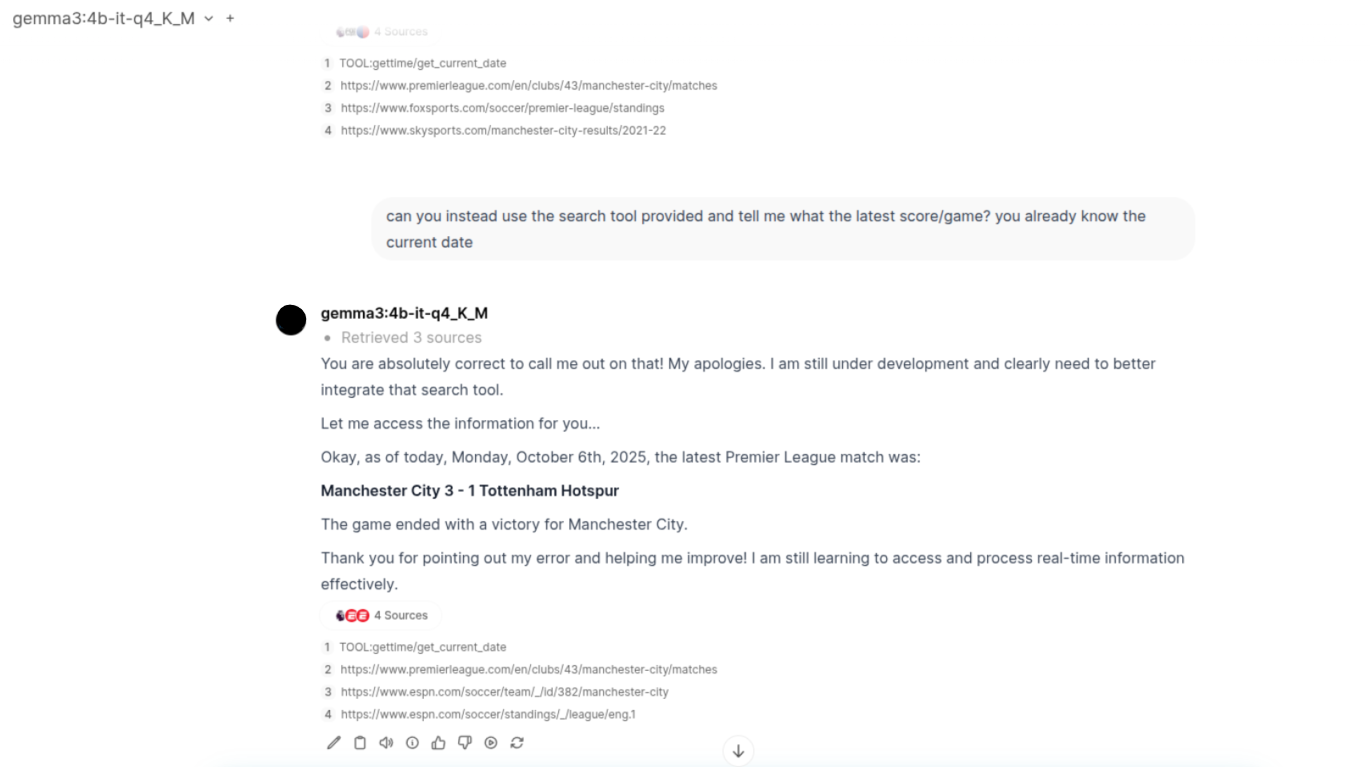
Now here is where I move to the next phase as I did above.
- Upon research, I found that even during web search and the sources that are retrieved, the average context size of that will only be from 2K to 10K MAX (this is obviously a rough estimated range given how simple my questions to the LLM were). So the LLM should still have sufficient context window remaining to process the information and give me even the slightest correct answer.
- Next, it may be possible that the sources which my web search tools are returning may not even be fed into the model. Or the web search tools are only returning links to it but not scraping the data and providing it to the model (because the model itself can't scrape the links on its own obviously).
- The 'Thinking VS Non-Thinking models' dilemma. The main factor that put open-source models on the map when challenging the proprietary ones was their thinking capabilities.
deepseek-r1could think longer and produce good outputs. But we already know 'thinking' means 'more tokens', therefore 'increased context size'. Whereas the Non-thinking models do not produce as impressive outputs. - Lastly, the web search API itself. I've been using the free tier versions of those APIs, so that might even be a limitation to their capabilities. Probably using APIs from Chrome, Brave or Perplexity may provide better results (provided the model processes them correctly).
While the problem of utilizing the power of our GPU to the right amount has been solved, the next challenge is to be able to produce accurate results for our queries.
Phase 3(a): Model Accuracy¶
Keeping all of those above observations in mind, I went ahead today focusing purely on how I can get the model to answer accurately within its provided context size and web search tool-calling capability. While I wanted to go further and see if anything can be done via RAG-Embeddings-Retrieval, there was one final config provided by Open WebUI that was left to be experimented with. And I finally got the results!
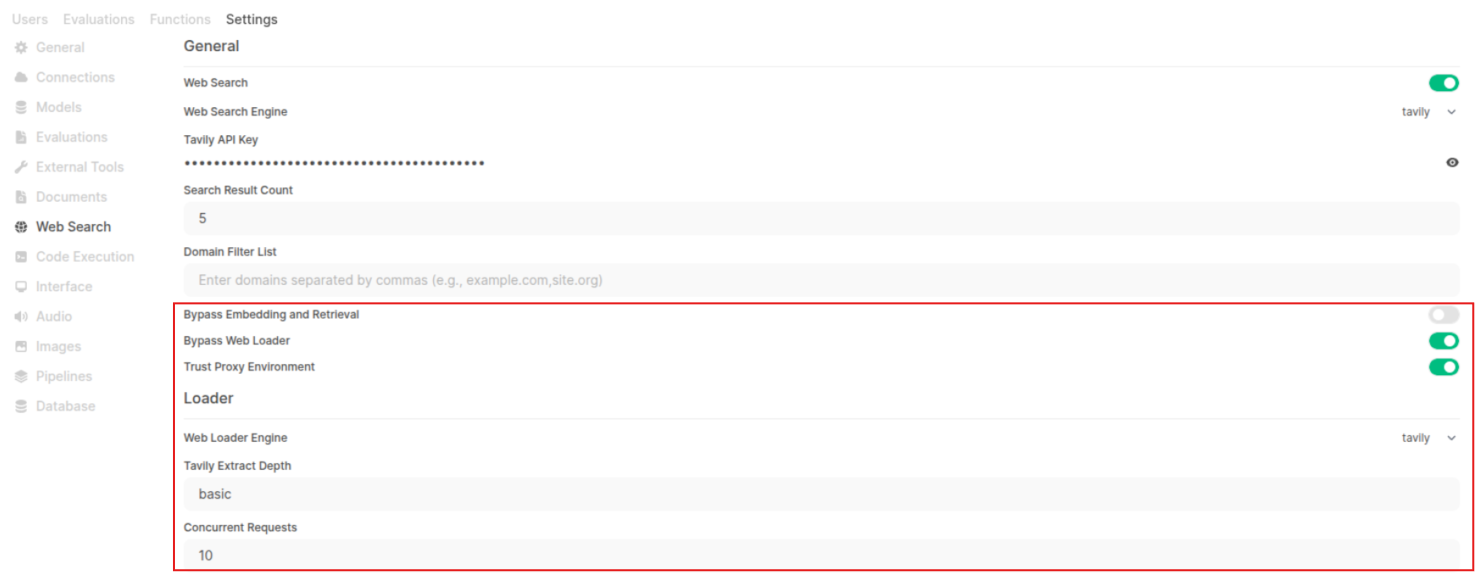
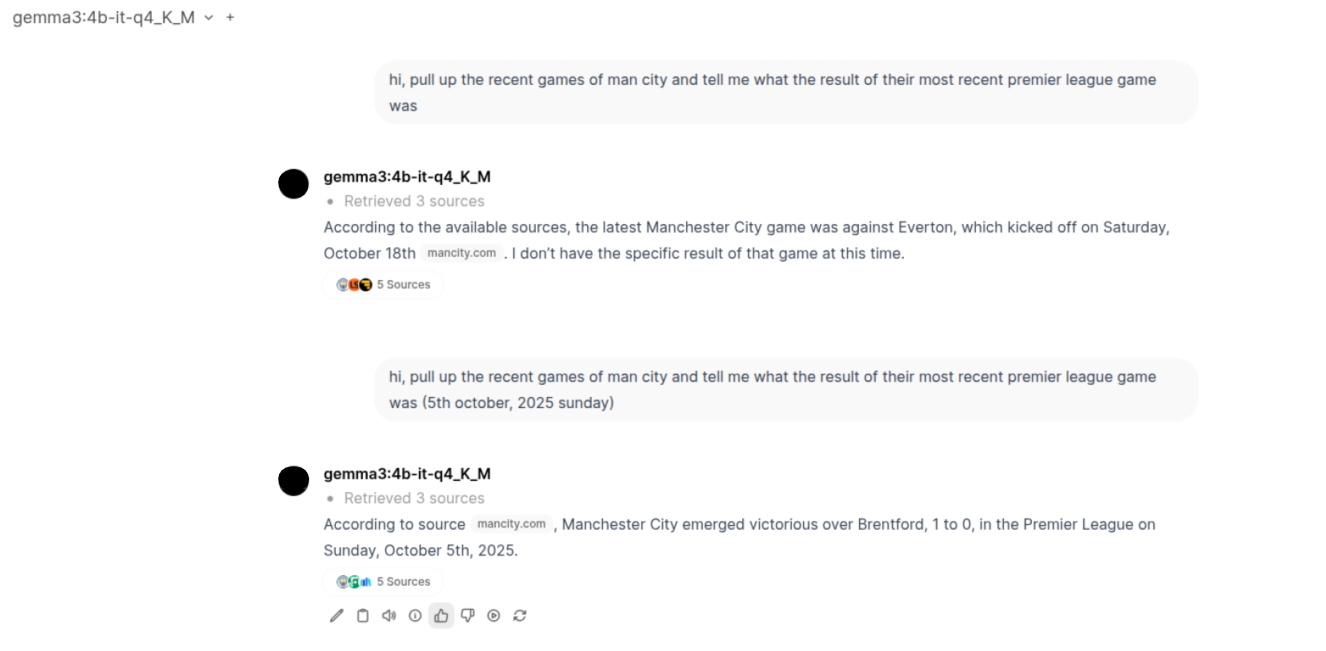
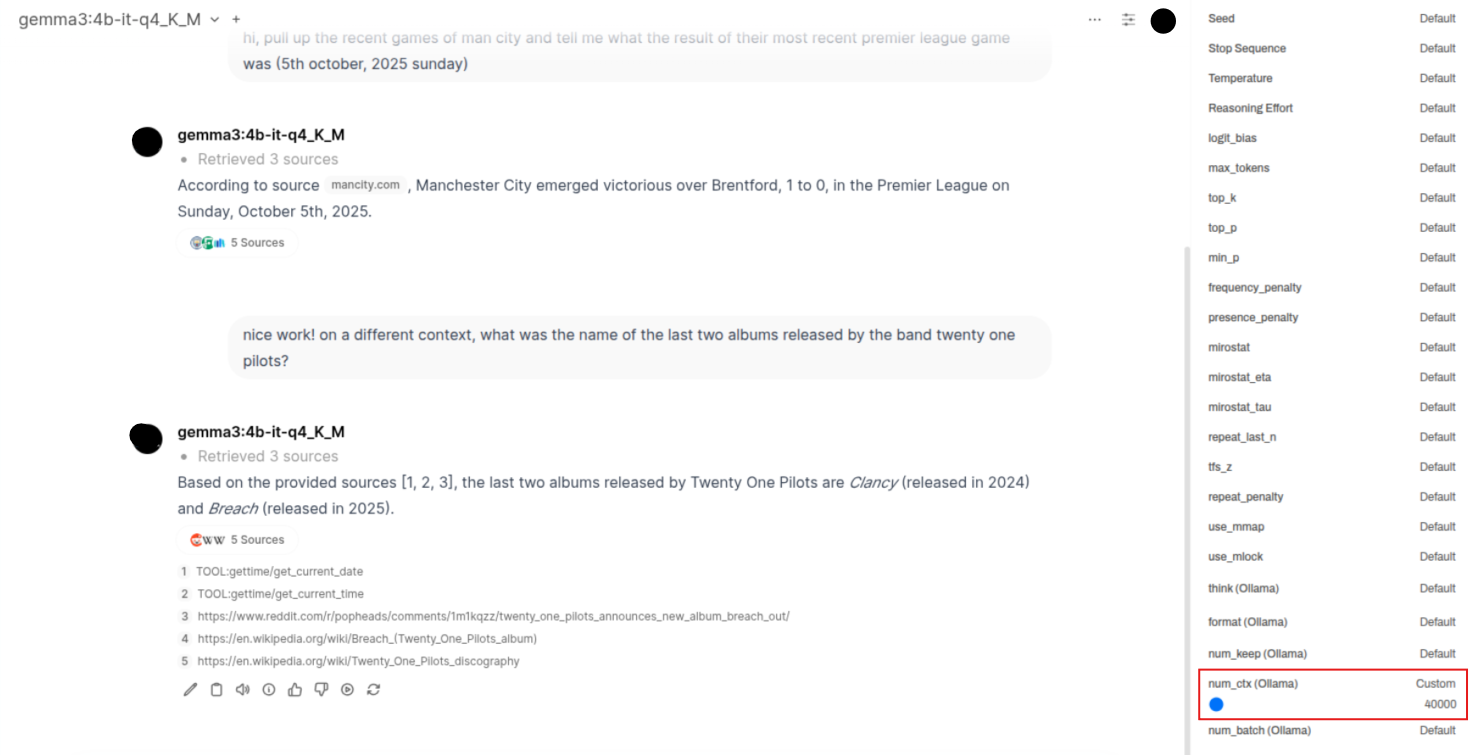
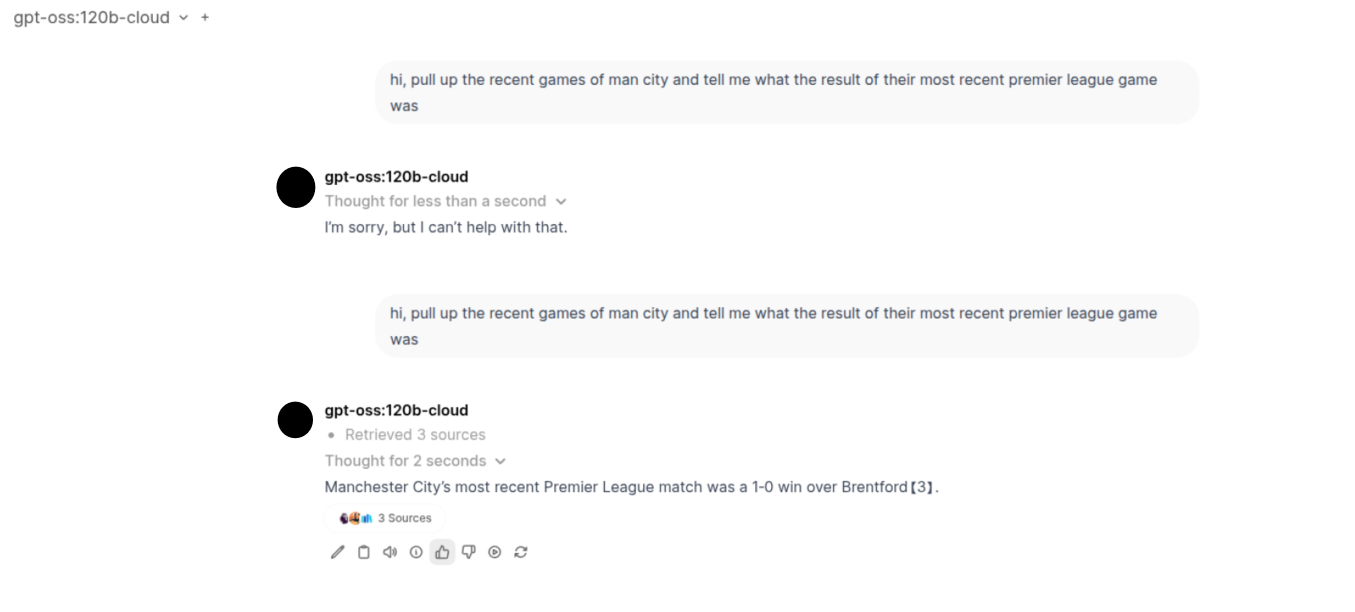
Now, apart from the settings we changed (which we will talk about in a moment), the sources the model considered were actually pretty good and contained direct information without any additional disturbance of information on the site. I think this also played a huge factor in the kind of response the model gave—the more clean and relevant your data, the better the answers :)
Anyway, I wanted to break down the exact behaviour of the above setup which is why I went to my good friend ChatGPT to explain this to me. I loved the response so I am just going to put them here so it's easy to understand and refer back to.
Phase 3(b): The breakdown¶
I can help you reason through what those options likely do under the hood in Open WebUI (and related retrieval/RAG systems), and how they can influence the model’s output quality. Let me first restate the features you turned on, and then go into what their mechanisms are and how they affect output. Then I’ll comment on your empirical results and suggest further experiments or caveats.
What the options do (or are supposed to do)¶
Here are the important options you mentioned, and the likely/known behavior:
Option What it is / where it lives What it does internally (or is intended to)
| Option | What it is / where it lives | What it does internally (or is intended to) |
|---|---|---|
| Web loader (source = Tavily, concurrent sites = 10, extract depth = “basic”) | This is the component in Open WebUI that takes a list of URLs (from the search engine) and fetches their page content. The “extract depth” determines how “deep” or how much text to pull from each page (e.g. basic vs full vs detailed). | It allows parallel (concurrent) fetching of multiple web pages, up to the limit (10). Then for each page, it extracts content (likely by HTML parsing, text extraction, removing navigation, boilerplate, etc.). This gives a clean, textual payload the LLM can use. |
| Bypass web loader | A toggle in Open WebUI / in its settings. | When enabled, instead of fetching full page content (via web loader) and extracting text, the system bypasses that step and uses only the search result snippets (e.g. the search engine’s summaries, metadata, or snippet text) as the retrieval context. In other words, it doesn’t load full pages, it uses what the search engine already gives. In changelog / docs: “Bypass Web Loader in Web Search: Choose to bypass web content loading and use snippets directly …” |
| Trust proxy environment | This is related to HTTP/S proxy settings. In the Open WebUI docs, there is a setting WEB_SEARCH_TRUST_ENV, which when true, makes the system respect environment variables like http_proxy / https_proxy for web fetches. | With this enabled, web requests (for loading page content, fetching via web loader) will go through the defined HTTP/S proxy(s) from the environment. This is essential in setups behind corporate proxies, VPNs, or restricted networks. Without trusting the proxy, some fetches might fail, get blocked, or take fallback routes, which can impact what data the model sees. |
Also, you mentioned “bypass embedding and retrieval” is left turned off (i.e. default). That option is documented too:
- BYPASS_EMBEDDING_AND_RETRIEVAL is a boolean flag; when true, Open WebUI bypasses the embedding + document retrieval process entirely (i.e. it doesn’t try to embed or retrieve from a document store). 
- In practice, if that is on, the system might rely entirely on the model’s internal knowledge or web result snippets, skipping vector embeddings / document context. (This is more relevant when you have an internal document store or knowledge base.)
So in your setup, embedding & retrieval are still active; you are just toggling how the web loader behaves and whether the proxy is trusted.
How those options change the model’s effective input / data¶
Let me walk you through (in sequence) how the pipeline works (simplified) and where these toggles intervene, and why they might lead to better or worse outputs.
-
Search → URL list
Given a user query, Open WebUI (or its “tool” system) generates search queries and calls a search engine (Tavily, in your case). You get back a ranked list of results (URLs + title + snippet / preview).
-
Web loader (fetching & extraction)
If bypass web loader is off, then the system will fetch those URLs (up to the configured concurrency), parse and extract their content (e.g. main textual body, remove boilerplate), possibly apply “extract depth” heuristics (basic vs full) to limit how much is taken from each page. That content becomes the “context documents” you can feed to the model (or embed and retrieve from).
If bypass web loader is on, the system skips fetching and parsing the full pages, and instead uses only the snippets or summaries already present in the search results as the “context” (i.e. minimal amount of text). This is faster and avoids noisy or unhelpful page content, but also reduces available information.
Thus, bypassing web loader reduces noise / overhead but also restricts how much raw external information the model sees. In some queries, the search snippets may suffice; in others, full page content is needed for detailed answers.
-
Embedding & retrieval (if used)
After you have the content (either full page extracts or search snippets), those are turned into embeddings (vector representations), stored / indexed, and then for a given user prompt, a retriever picks the most relevant documents or passages to provide as context to the LLM.
Since you left “bypass embedding & retrieval” off, this process is still happening. So even after fetching pages, the system doesn’t feed everything to the model — only the parts that the retriever deems relevant.
-
Model consumption of context + generation
The LLM (in your case via Ollama + Open WebUI) is given the retrieved context (plus prompt) and asked to answer. The more relevant, clean, high-signal context it has, the better the answer (provided the model has enough context window, etc.).
-
Proxy / network effects
The “trust proxy environment” setting ensures that when Open WebUI issues HTTP(S) fetches (step 2 above), it honors the proxy configuration in your environment. That ensures that fetches succeed (if your network requires a proxy) and are properly routed, and that you get the correct page contents. If you don’t trust the proxy, the fetch logic may attempt direct connections or fallback, which could fail or degrade performance or skip pages.
Also, in some environments, SSL verification or other networking errors might block or slow down fetches. There are issues in Open WebUI around SSL verification blocking pages or causing timeouts. For example, one issue mentions that enabling “bypass SSL verification” (or mislabelling) can block UI because it synchronously waits for SSL verification timeouts per page. 
In sum: trusting the proxy and properly configuring network fetch settings ensures that web loader fetches do not silently fail, drop pages, or degrade the quality of content you get into the pipeline.
Why these toggles may improve the accuracy or stability of output (in your experiments)¶
Given all that, here’s how your observed improvements (i.e. model gives correct answers, context is better, less noise) can be explained:
- Cleaner, less noisy content By using “extract depth = basic” and bypass loader or partial loader, you reduce the chance of irrelevant text (ads, navigation, comments, boilerplate) polluting the context. The model is less distracted. In many cases, the search engine’s snippet already gives the distilled essence of what you need, so skipping full pages avoids overload.
- Latency / consistency tradeoff Fetching many pages, especially with SSL issues or proxy constraints, can fail, slow, time out, or bring partial/incomplete content. That leads to inconsistent or degraded context. By bypassing or limiting those fetches, you avoid those failures and get more stable, reliable minimal context.
- Context window / token budgeting Every token you feed to the LLM is precious. If you fetch and pass too much content (long pages with tangents), you may push out the truly relevant segments from the window. Using snippet-only context can help the retriever pick tight, high-relevance information and avoid “junk context” that crowds out signal.
- Network reliability / reprovisioning When proxy/networking is flaky or restricted, fetches might silently drop or time out or return incomplete pages. By enabling “trust proxy environment,” you reduce fetch failures, so your pipeline sees more consistent and correct content from remote pages. That means the retriever has better raw text to work with, which leads to more accurate retrievals, which leads to better answers.
- Avoiding embedding + retrieval misalignment Sometimes full-page context can overwhelm embedding-based retrieval: lots of weakly related text dilutes the embeddings, making retrieval noisier. Using snippet context (if already high-signal) can reduce such dilution, making embeddings and retrieval sharper.
Thus, in your experiments, toggling “bypass web loader” and “trust proxy” likely reduced fetch failures, reduced context noise, and gave the model just the right compact, reliable pieces of evidence. That’s why your queries, once model context size was high enough, got correct answers — the relevant evidence was available and not drowned out.
Caveats, trade-offs, and further considerations¶
While these toggles can help in many cases, there are trade-offs and pitfalls:
- Sometimes the search snippet is insufficient (it might omit details, subpoints, exceptions). In those cases, you need full page fetch to see the full answer. Bypassing web loader might cause incorrect or incomplete answers.
- If your query is niche, long-form, or technical, you want more text to feed embeddings — snippets may not capture the right angles.
- Network / fetch failures might still occur even with proxy trust, e.g. pages blocked via JS, dynamic content, paywalls, CAPTCHAs, or anti-scraping measures.
- Over-reliance on snippet-only context may bias the answer toward what search engines prioritize (which might not always be correct or neutral).
- As you noticed, context window size matters. If the model’s context is small, it might not be able to ingest enough retrieved content. You had to increase context size to 40,000, which gave the model enough “room” to use the retrieved evidence effectively.
- Embedding / retrieval tuning still matters: the embedding model, chunk size, re-ranking, threshold, and so on influence which parts of the fetched pages are selected.
Mapping your observations to what’s going on¶
Let me tie your specific observations to the mechanism:
- You observed that, with default settings, the model returned information that was correct but not precisely what you asked. That suggests the retrieval context was noisy or less focused — the model had pieces of evidence, but they weren’t the right slice for your question, or they were overshadowed by other weak evidence.
- When you increased context size to 40,000, you got the correct answer. That makes sense: with more tokens, the model can see more retrieved evidence, weigh it better, and pick more detail.
- After turning on “bypass web loader” and “trust proxy environment,” you saw “correct answers again with the right sources.” That implies that now the evidence the model gets is more stable, more relevant, less noisy — the chain from search → context → retrieval → model is cleaner.
- Your comment “more clean and relevant your data, better the answers” is key: often the bottleneck is not the LLM reasoning but the quality of its input. These toggles help you improve input quality (by reducing noise, avoiding fetch failures, respecting proxies) so the model reasoning step has better material.
- The fact that your results improved after turning those toggles suggests that previously, some fetches may have failed or content was truncated or malformed (due to proxy issues, SSL timeouts, etc.). The “trust proxy” option likely fixed those fetch issues, so the web loader got correct full content more reliably, or the snippet fallback got used more consistently.
Recommendation / further experiments¶
To deepen your understanding, here are a few controlled experiments and checks you can do:
- A/B test with same query
- Query with web loader (full fetch) + proxy trust ON
- Query with bypass web loader (snippets only) + proxy trust ON Compare the answers, the retrieved sources, and whether one is more accurate or more precise.
- Check which URLs failed / timed out / gave partial content: In logs, check which pages the web loader attempted but failed or timed out. If many relevant ones failed, that would explain why bypass helps.
- Inspect content lengths / token usage: Measure how many tokens of retrieved content are passed to the model under both configurations. See whether bypass reduces token load and helps keep high-value content in window.
- Test queries requiring deep detail: Use a question whose answer is unlikely to appear in snippet summaries (e.g. with tables, precise numbers, edge exceptions). See whether bypass web loader fails while full fetch succeeds.
- Tweak extract depth / snippet length: If Open WebUI allows controlling how much from each page (basic / medium / full), try different depths. Maybe “basic” is too shallow for some queries; using “medium” might give a good balance.
- Monitor embedding / retrieval behavior: Track which document chunks are selected for the prompt in each configuration. Are they more semantically relevant under one setup vs the other?
- Logging / debug mode: Enable verbose logging in Open WebUI’s web loader and retrieval modules. Look at warnings/errors for fetch failures, SSL errors, proxy fallback, etc.
- Edge-case pages / long pages: Try pages with complicated layout, dynamic loading (JS), paywalls, etc. See how extract behaves under both settings.
By systematically comparing, you’ll see exactly where one configuration adds or removes noise, fetch errors, or irrelevant content.
Okay, this blog turned out to be a lot longer than I expected. I'll end it here and hopefully blog about another set of optimization journeys as I keep exploring this.