
Agentic AI (My course notes)¶
All code implementations can be found in my repository on github
Introduction to Agentic Workflows¶
What is Agentic AI?¶
An agentic AI workflow is a process where an LLM based app executes multiple steps to complete a task.
Knowing how to decompose the task into steps and how to build the components to execute the individual steps turns out to be a tricky but important skill that will determine our ability to build agentic workflows for a huge range of exciting applications.
Lets say we are building a comprehensive research agent- So when asked a query (like, how can we complete with SpaceX?) this agent starts with planning out what research to use, including calling a web search engine to download some web pages, and then to synthesize and rank findings, draft an outline, have an editor-to-agent review for coherence, and then finally generate a comprehensive markdown report. So, the final output will be on building a new rocket company to compete with SpaceX with an intro, background, findings, and so on.
Now, one of the often-discussed areas of AI agents is how autonomous are they? What we read above was a relatively complex, highly autonomous Agentic AI workflow, but there are also other simpler workflows that are incredibly valuable.
Degrees of autonomy¶

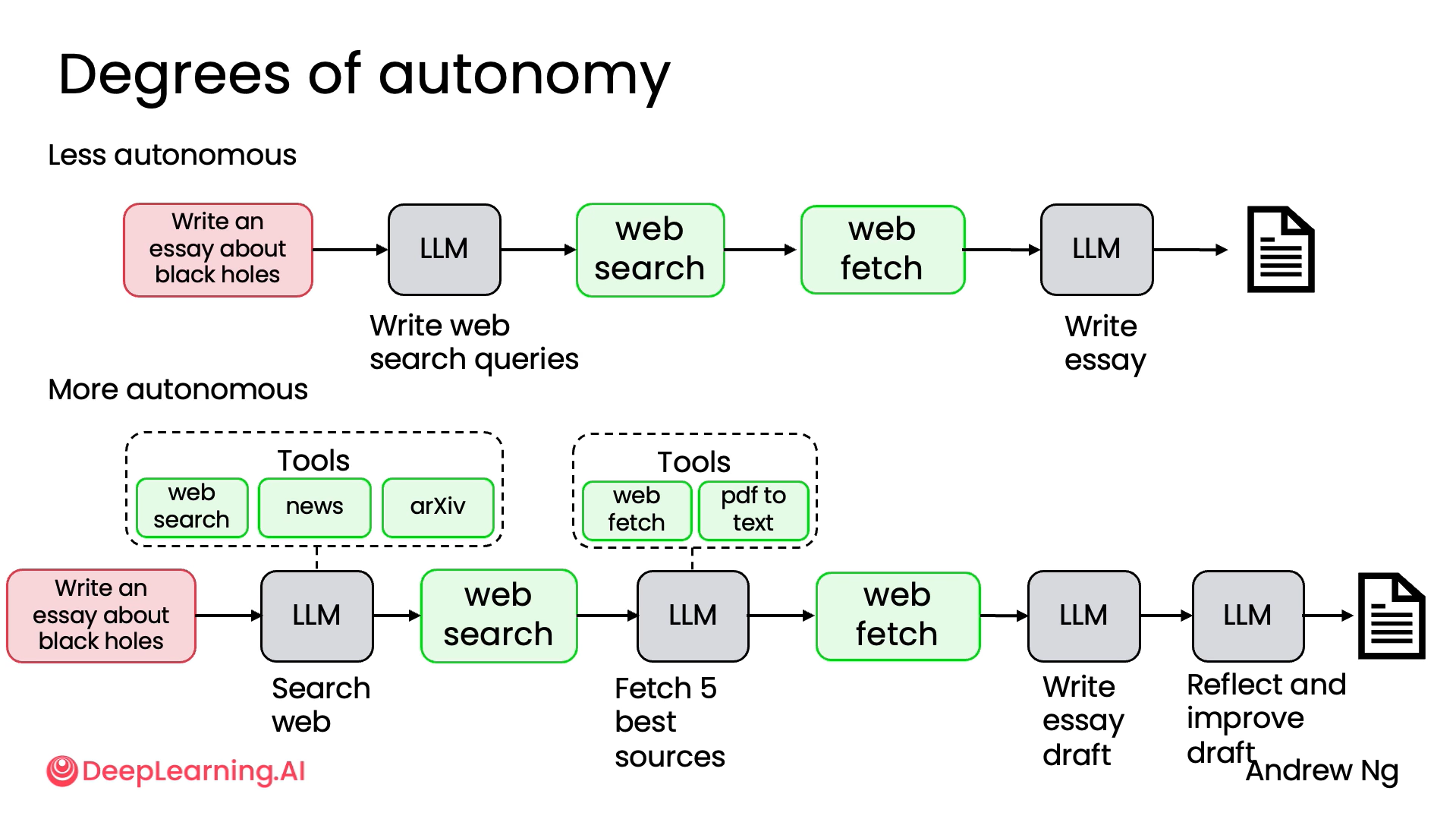
Keeping the above diagram in mind, You will find that there are tons of applications in the less autonomous end of the spectrum that are very valuable being built for tons of businesses today, and at the same time, there are also applications being worked on at the more highly autonomous end of the spectrum, but those are usually less easily controllable, a little bit more unpredictable, and also a lot of active research as well to figure out how to build these more highly autonomous agents.
Benefits of Agentic AI¶
I think the one biggest benefit of agentic workflows is that it allows you to do many tasks effectively that just previously were not possible. But there are other benefits as well, including parallelism (which we will talk about after the coding benchmark example) that lets you do certain things quite fast, as well as modularity that lets you combine the best of three components from many different places to build an effective workflow.
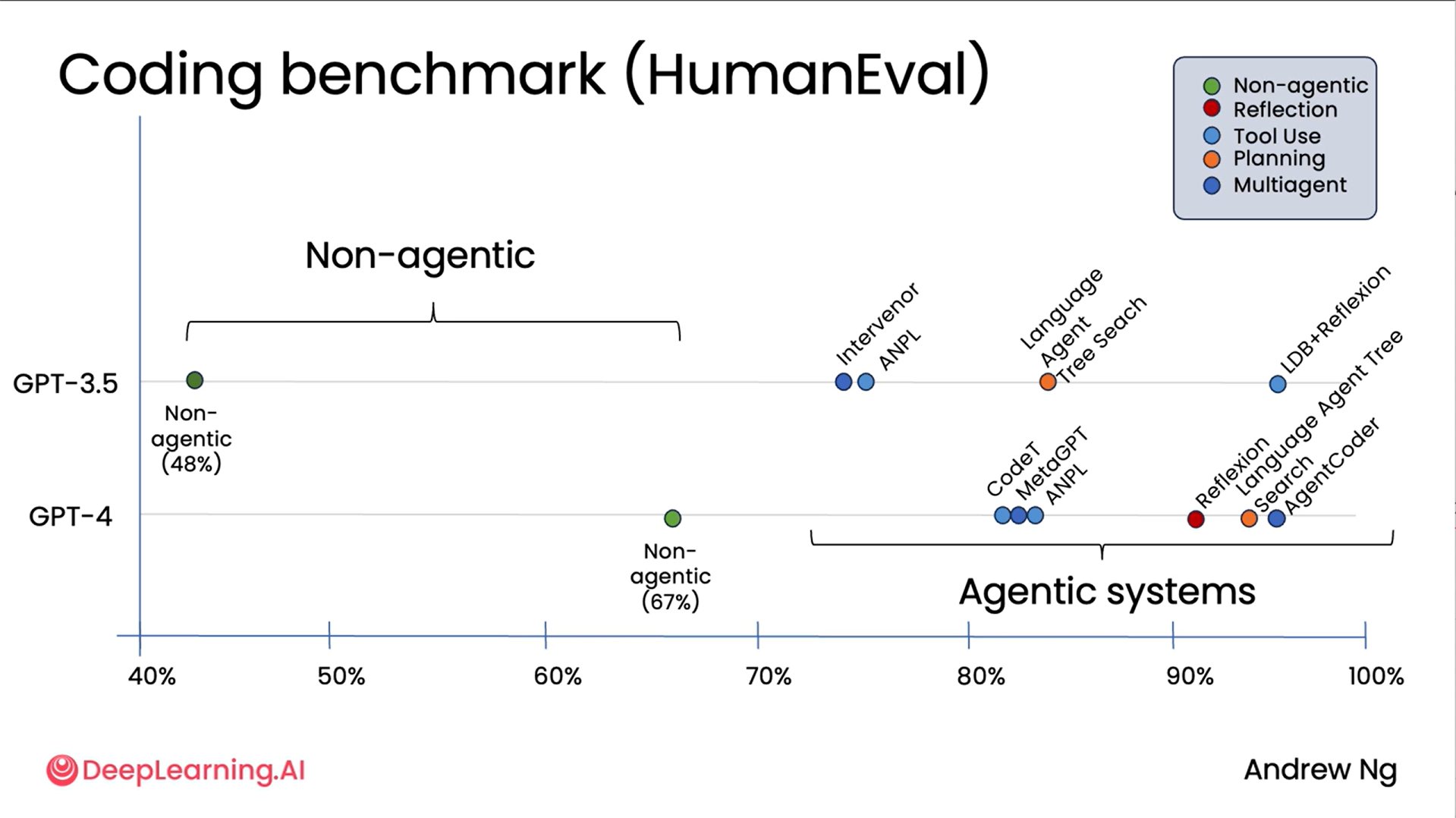
First comes Coding Benchmark: The diagram above shows us the data on a coding benchmark that tests the ability of different LLMs to write code to carry out certain tasks. The benchmark used in this case is called Human Eval. It turns out that GPT 3.5, if asked to write the code directly, gets 40% right on this benchmark. This is a positive k-metric. GPT 4 is a much better model. Its performance leaps to 67% with this also non-agentic workflow.
But it turns out that as large as the improvement was from GPT 3.5 to GPT 4, that improvement is dwarfed by what you can achieve by wrapping GPT 3.5 within an agentic workflow.
Using different agentic techniques (which we will learn more on later), you can prompt GPT 3.5 to write code and then maybe reflect on the code and figure out if you can improve it. And using techniques like that, you can actually get GPT 3.5 to get much higher levels of performance. And similarly, GPT 4 used in the context of an agentic workflow also does much better.
So even with today's best LLMs, an agentic workflow lets you get much better performance. And in fact, what we saw in this example was the improvement from one generation of model to another, which is huge, is still not as big a difference as implementing an agentic workflow on the previous generation of model.
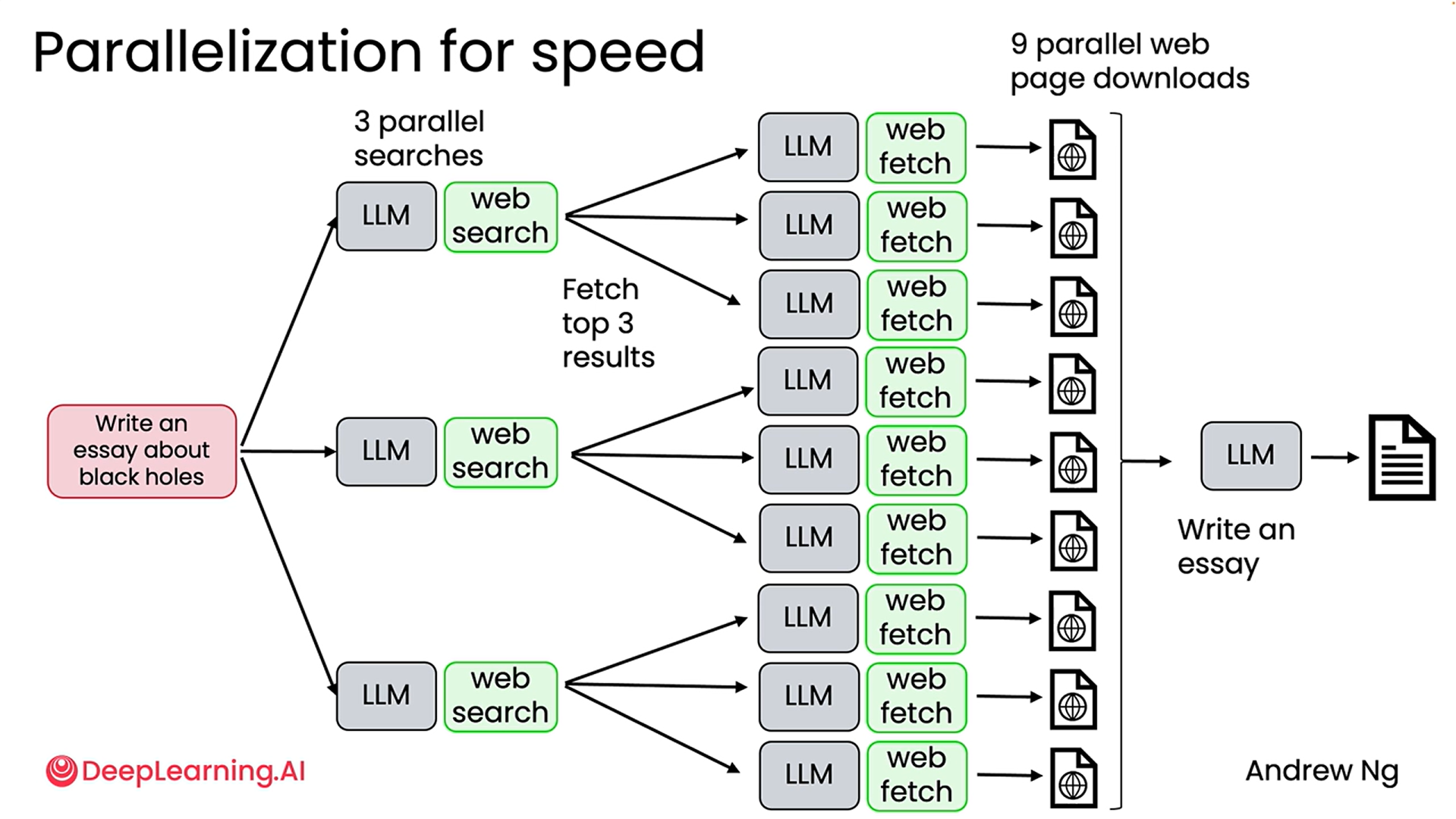
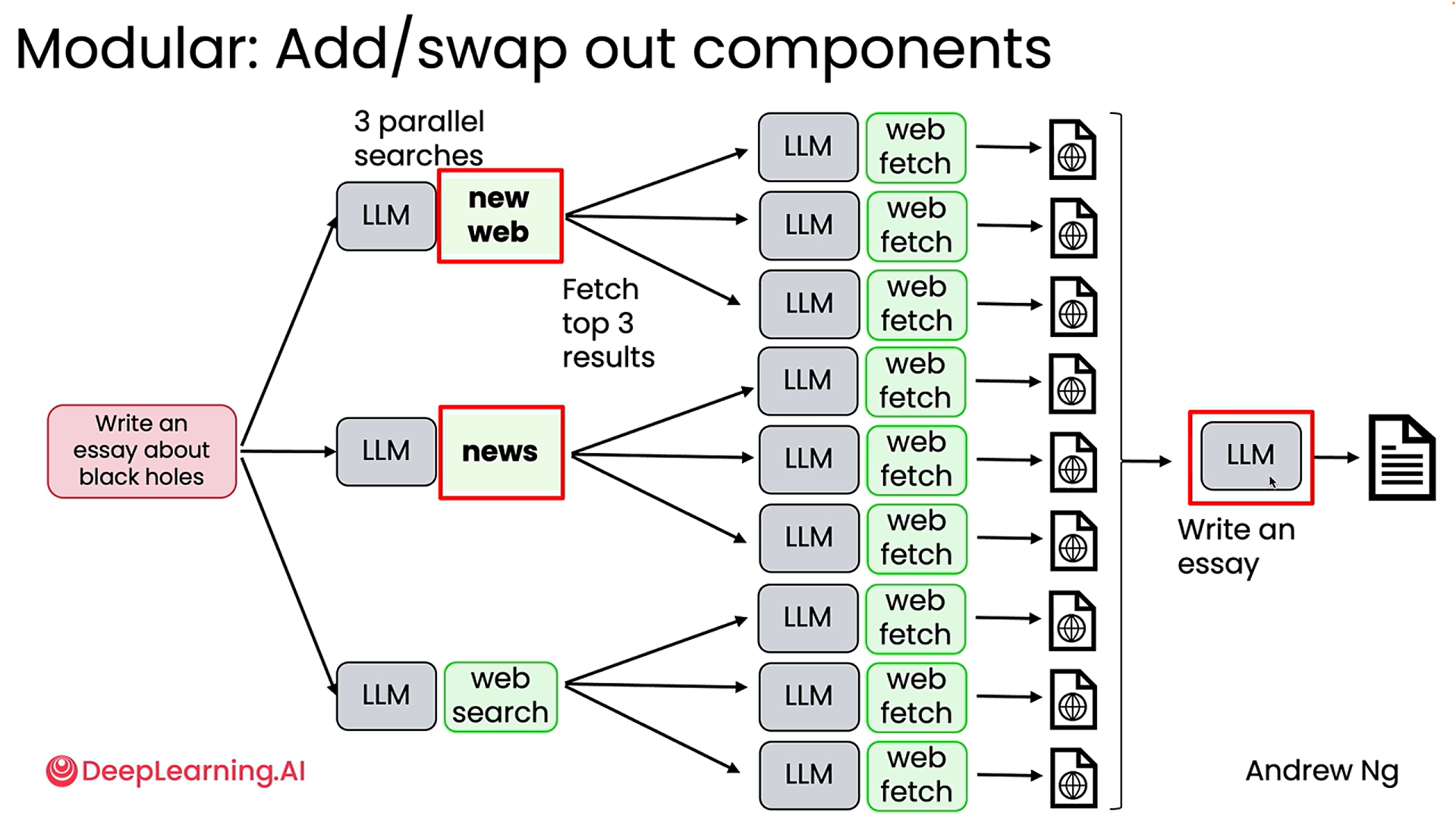
Next comes Parallelization: This is another benefit of using agentic workflows where they can parallelize some tasks and thus do certain things much faster than a human. The first diagram shows how it can do almost 9 web searches at once. Second diagram shows how we can experiment with it by changing the specific components like the search API or even trying out different LLMs rather than sticking with just one for all the different steps, to see which modifications can provide better outputs for our task.
Agentic AI Applications¶
Here we’ve seen the different types of agentic applications currently in use, like customer service etc. The main point to takeaway would be the below diagram which shows how easy/hard it is to build your agent based on what you have.
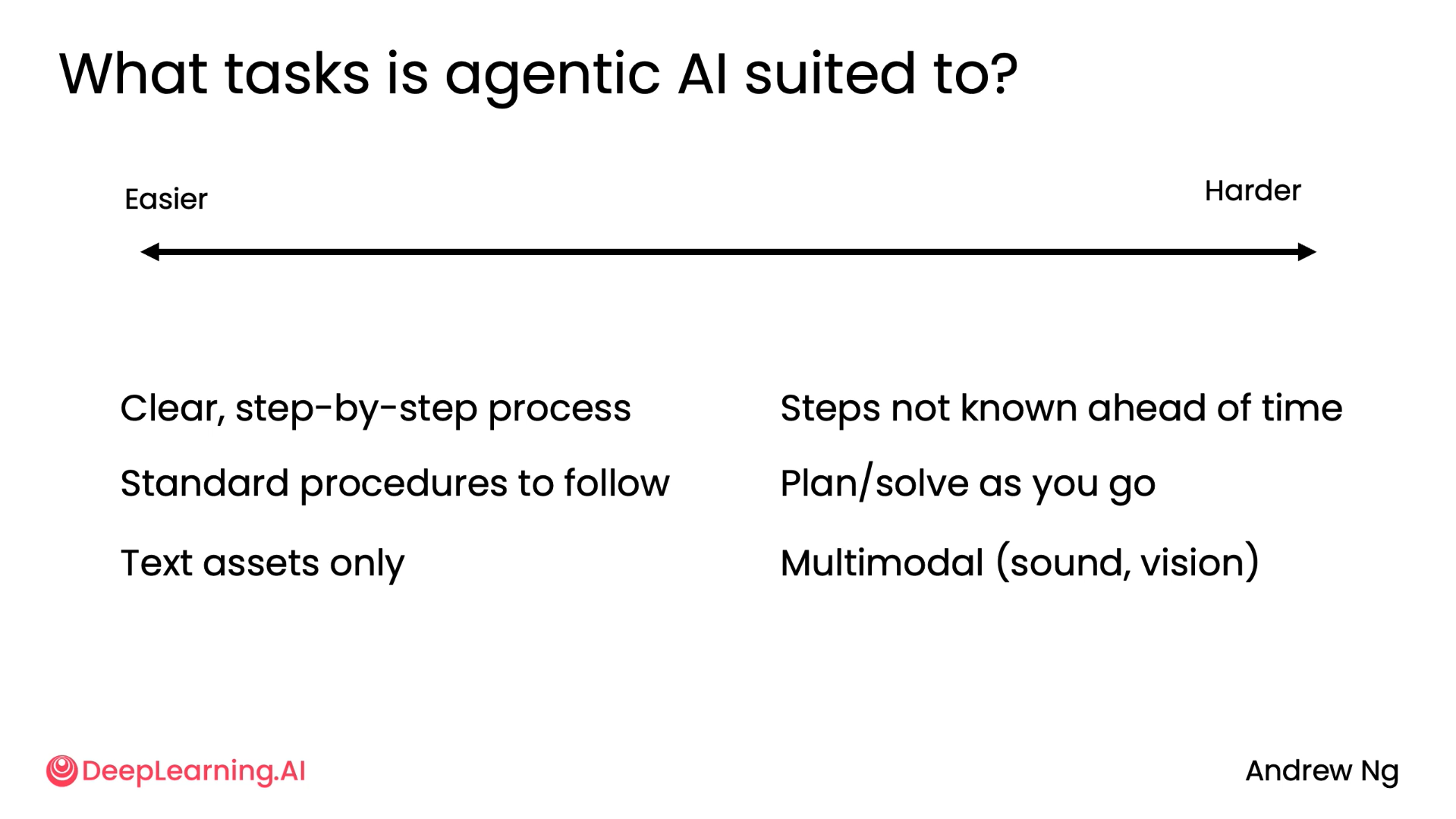
So, when implementing one of these things yourself, one of the most important skills is to look at a complex workflow and figure out what are the individual steps so you can implement an agentic workflow to execute those steps one at a time. And that is exactly what we will be looking at in Task decomposition.
Task decomposition¶
One of the key skills in building agentic workflows is to look at a bunch of stuff that maybe someone does and to identify the discrete steps that it could be implemented with.
And when I'm looking at the individual discrete steps, one question I'm always asking myself is, can this step be implemented with either an LLM or with one of the tools such as an API or a function call that I have access to? And in case the answer is no, I'll then often ask myself, how would I as a human do this step? And is it possible to decompose this further or break this down into even smaller steps that then maybe is more amenable to implementation with an LLM or with one of the software tools that I have?
Evaluation (evals)¶
"Your ability to drive evals for your agentic workflow makes a huge difference in your ability to build them effectively."
There are some simple ways to evaluate your agent like:
- You can write codes to evaluate objective criteria, such as 'did it mention a competitor or not'.
- Using an LLM as a judge for more subjective criteria such as 'what's the quality of this essay'.
But later, we will learn about two major types of evals:
- One is end-to-end, where you measure the output quality of the entire agent.
- Other is component level evals, where you measure the quality of the output of a single step in the agentic workflow.
It turns out that these are useful for driving different parts of your development process.
There is another method apart from this where you just examine the intermediate outputs - we call these the traces of the LLM, in order to understand where it is falling short of my expectations. And we call this error analysis, where we just read through the intermediate outputs of every single step to try to spot opportunities for improvement.
Agentic design patterns¶
- Reflection
- Tool Use
- Planning
- Multi-agent collaboration
(There were some great slides which showed examples on the above, feel free to watch that. But since we will be diving deep into this as well, I didn't want to get hung around in just the overview stuff for now).
Update: Also damn, the quiz was slightly more tricky than I thought it would be lol. But its done and I also tried out the research agent which was already developed by sensei, you can checkout it's output here, very impressive actually. Now we move on!
Reflection Design Pattern¶
Reflection to improve outputs of task¶
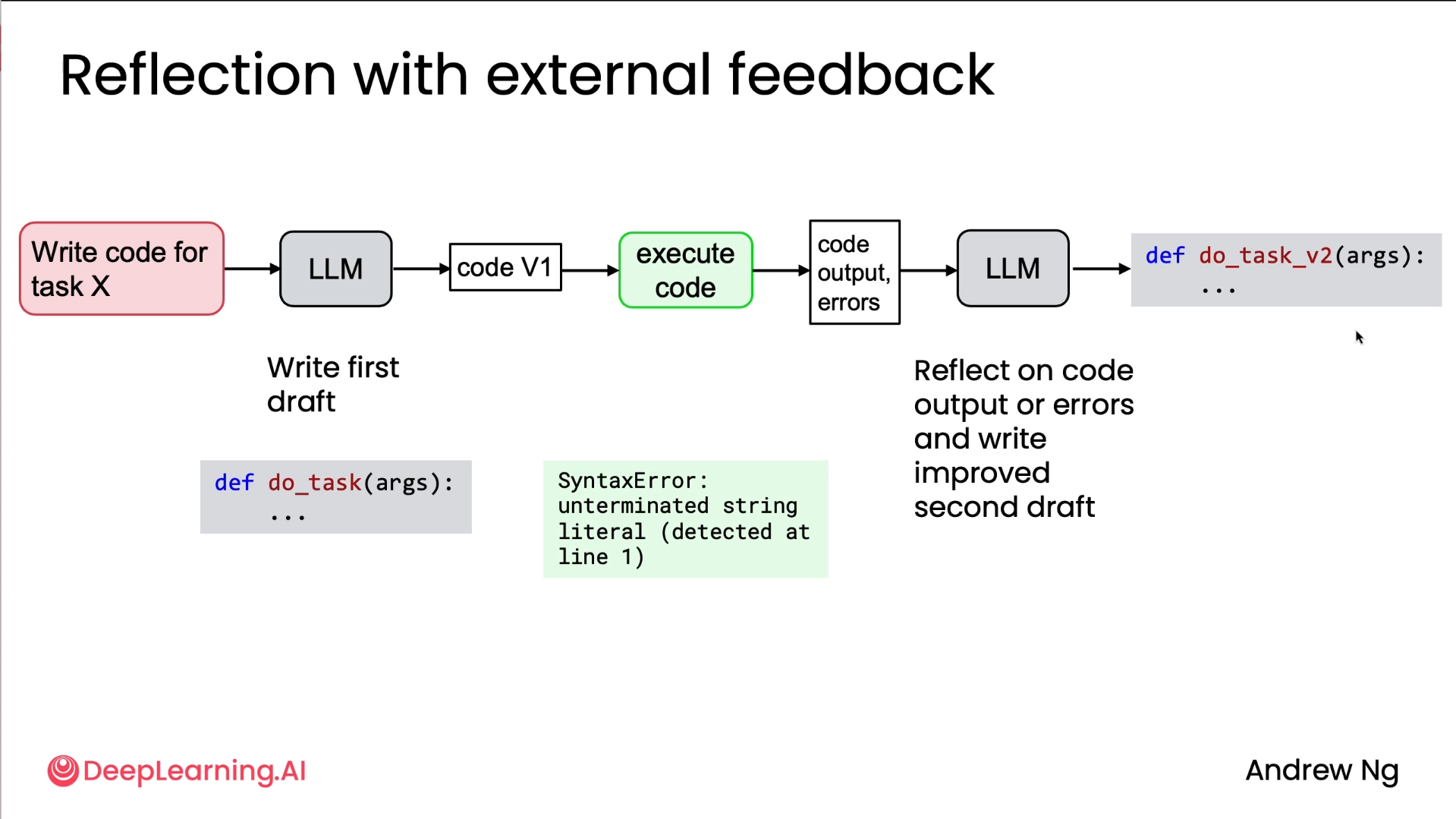
One design consideration to keep in mind is, reflection is much more powerful when there is new additional external information that you can ingest into the reflection process.
For example, if you can run the code and have that code output or error messages as an additional input to the reflection step, that really lets the LLM reflect much more deeply and figure out what may be going wrong. This results in a much better second version of the code than if there wasn't this external information that you can ingest. So one thing to keep in mind, whenever reflection has an opportunity to get additional information, that makes it much more powerful.
The attached diagram shows exactly that, where rather than just feeding the provided code from step 1 back into reflection, we execute it ourselves and give additional data for reflection, therefore providing us with a better output.
Reflection does not make an LLM always get everything right 100% of the time, but it can often give it maybe a modest bump in performance.
Why not just direct generation?¶
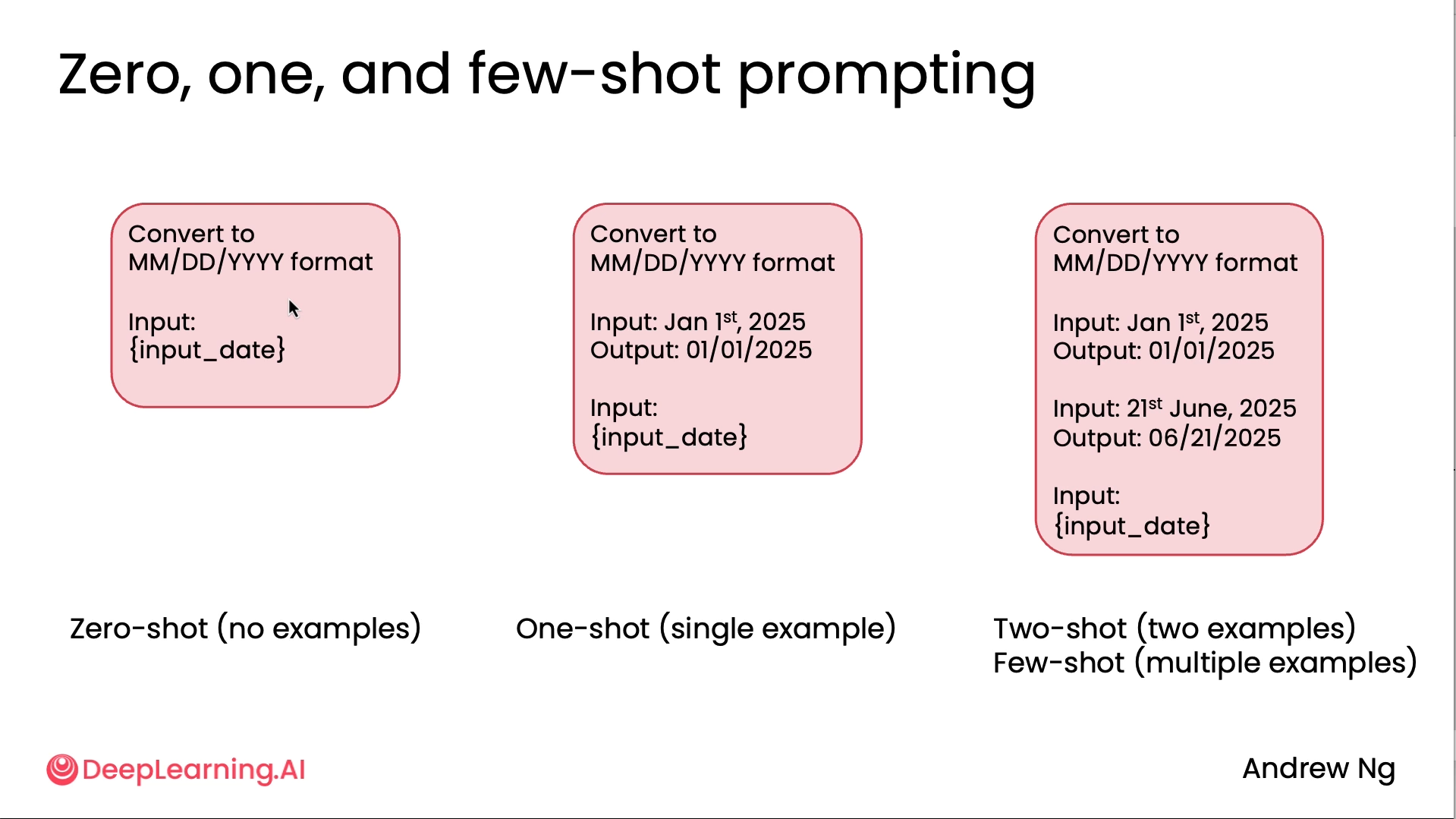
Direct generation aka Zero shot prompting. There are different types of how we can provide all possible information to the LLM.
Below diagram is adapted from the research paper by Madaan and others, and this shows a range of different tasks being implemented with different models and with and without reflection. The way to read this diagram is to look at these pairs of adjacent light followed by dark-colored bars, where the light bar shows zero-shot prompting and the dark bar shows the same model but with reflection.
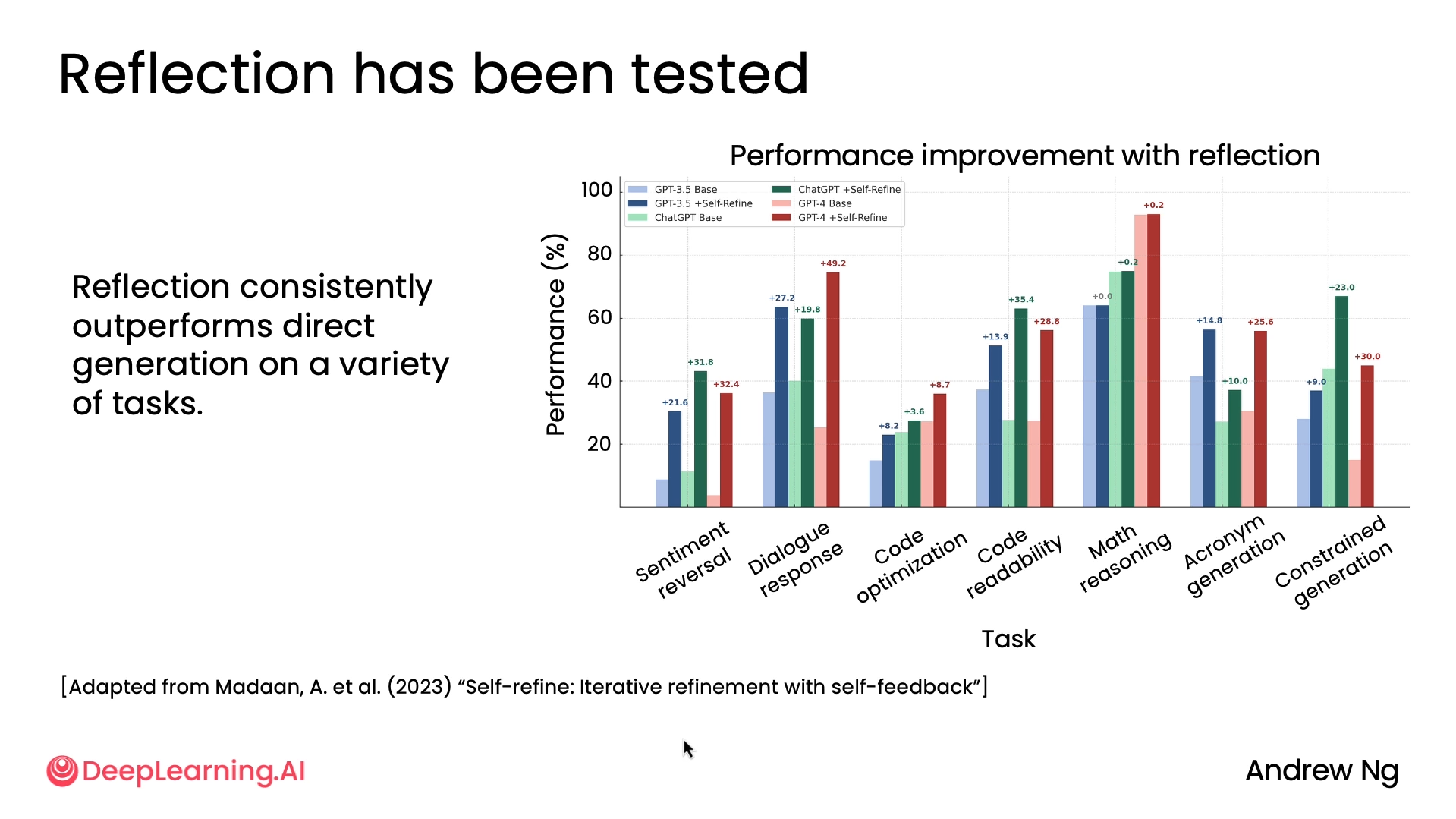
So some tips for writing reflection prompts: It helps to clearly indicate that you want it to review or to reflect on the first draft of the output. And if you can specify a clear set of criteria/instructions in points, such as whether the domain name is easy to pronounce and whether it may have negative connotations or for email, check the tone and verify the facts. Then that guides the LLM better in reflecting and critiquing on the criteria that you care the most about.
Chart generation workflow¶
This is a fun example where we'll start to look at multi-modal inputs and outputs. We'll have an algorithm reflect on an image being generated or a chart being generated.
Code for this can be found in the repo mentioned at the start of this blog!
One thing you may find is that sometimes using a reasoning model for reflection may work better than a non-reasoning model.
Now, when you're building an application, one thing you may be wondering is, does reflection actually improve performance on your specific application? From various studies, reflection improves performance by a little bit on some, by a lot on some others, and maybe barely any at all on some other applications.
And so it'll be useful to understand its impact on your application and also give you guidance on how to tune either the initial generation or the reflection prompt to try to get better performance.
Evaluating impact of reflection¶
Reflection often improves the performance of the system, but before I commit to keeping it, I would usually want to double check how much it actually improves the performance, because it does slow down the system a little bit by needing to take an extra step.
Let's take a look at evals for reflection workflows.
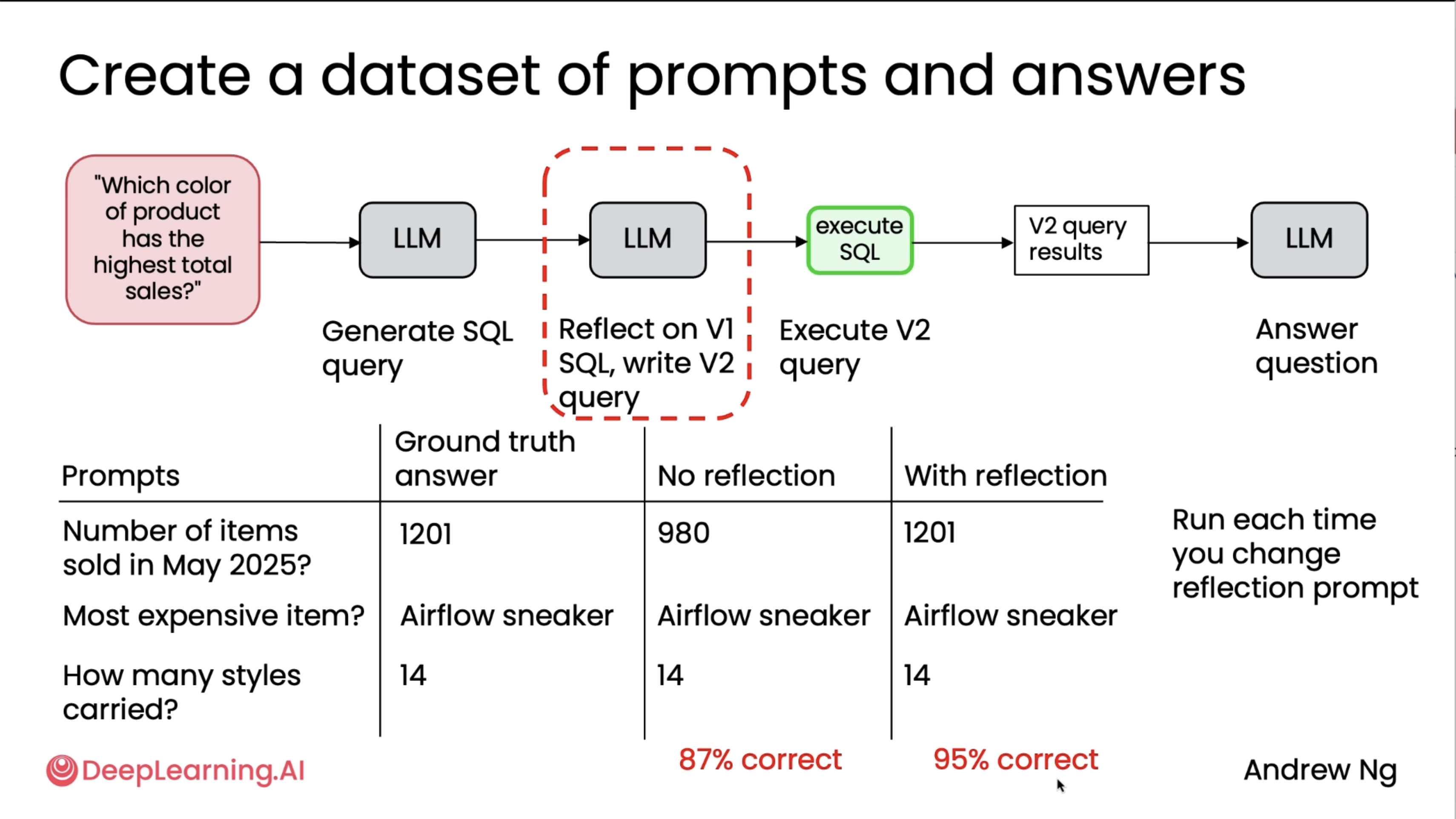
Let's look at an example of using reflection to improve the database query that an LLM writes to fetch data to answer questions. Let's say you run a retail store, and you may get questions like, which color product has the highest total sales? To answer a question like this, you might have an LLM generate a database query. After writing a database query, instead of using that directly to fetch information from the database, you may have an LLM, the same or different LLM, reflect on the version one database query and update it to maybe an improved one, and then execute that database query against the database to fetch information to finally have an LLM answer the question.
So the question is, does using a second LLM to reflect and improve on the database or SQL query actually improve the final output? In order to evaluate this, I might collect a set of questions or set of prompts together with ground truth answers. So maybe one would be, how many items are sold in May 2025? What's the most expensive item in the inventory? How many styles are carried in my store? And I write down for maybe 10, 15 prompts, the ground truth answer. Then you can run this workflow without reflection. So without reflection would mean to take the SQL query generated by the first LLM and to just see what answer it gives. And with reflection would mean to take the database query generated after the second LLM has reflected on it to see what answer that fetches from the database. And then we can measure the percentage of correct answers from no reflection and with reflection. In this example, no reflection gets the answers right 87% of the time, with reflection gets it right 95% of the time. And this would suggest that reflection is meaningfully improving the quality of the database queries I'm able to get to pull out the correct answer.
One thing that developers often end up doing as well is rewrite the reflection prompt. So for example, do you want to add to reflection prompt an instruction to make the database query run faster or make it clearer? Or you may just have different ideas for how to rewrite either the initial generation prompt or the reflection prompt. Once you put in place evals like this, you can quickly try out different ideas for these prompts and measure the percentage correct your system has as you change the prompts in order to get a sense of which prompts work best for your application. So if you're trying out a lot of prompts, building evals is important.
It really helps you have a systematic way to choose between the different prompts you might be considering. But this example is one of when you can use objective evals because there is a right answer. The number of items sold was 1,301 and the answer is either right or wrong. How about applications where you need more subjective rather than objective evaluations? In the plotting example that we saw in the previous example, without reflection we had the stack bar graph, with reflection we had this graph. But how do we know which plot is actually better? Measuring which of those plots is better is more of a subjective criteria rather than a purely black and white objective criteria. So for these more subjective criteria, one thing you might do is use an LLM as a judge.
And maybe a basic approach to do this might be to feed both plots into an LLM, a multi-modal LLM that can accept two images as input, and just ask it which image is better. It turns out this doesn't work that well as it turns out that there's some known issues of using LLMs to compare two inputs to tell you which one is better. First, it turns out the answers are often not very good. It could be sensitive to the exact wording of the prompt of the LLM as a judge, and sometimes the rank ordering doesn't correspond that well to human expert judgment. And one manifestation of this is many LLMs will have a position bias. Many LLMs, it turns out, will often pick the first option more often than the second option.
So, Instead of asking an LLMs to compare a pair of inputs, grading with a rubric can give more consistent results. So, for example, you might prompt an LLM to tell it, given a single image, assess the attached image against the quality rubric, and the rubric or grading criteria may have clear criteria like does the plot have a clear title, are the access labels present, is it an appropriate chart type, and so on, with a handful of criteria like this. Even here, it turns out that instead of asking the LLM to grade something on a scale of 1 to 5, which it tends not to be well calibrated on, if you instead give it, say, 5 binary criteria, 5-0-1 criteria, and have it give 5 binary scores, and you add up those scores to get the number from 1 to 5 or 1 to 10 if you have 10 binary criteria, that tends to give more consistent results.

And so if we're to gather a handful, say 10-15 user queries for different visualizations that the user may want to have of the coffee machine sales, then you can have it generate images without reflection or generate images with reflection, and use a rubric like this to score each of the images to then check the degree to which or whether or not the images generated with reflection are really better than the ones without reflection. And then once you've built up a set of evals like this, if ever you want to change the initial generation prompt or you want to change the reflection prompt, you can also rerun this eval to see if, say, updating one of your prompts allows the system to generate images that scores more points according to this rubric. And so this too gives you a way to keep on tuning your prompts to get better and better performance.
What you may find when building evaluations for reflection or for other agentic workflows is that when there is an objective criteria, code-based evaluation is usually easier to manage. And in the example that we saw with the database query, we built up a database of ground truth examples and ground truth outputs and just wrote code to see how often the system generated the right answer in a really objective evaluation metric. In contrast for small subjective tasks, you might use an element as a judge but it usually takes a little bit more tuning, such as having to think through what rubric you may want to use to get the LLM as a judge to be well calibrated or to output reliable evals.
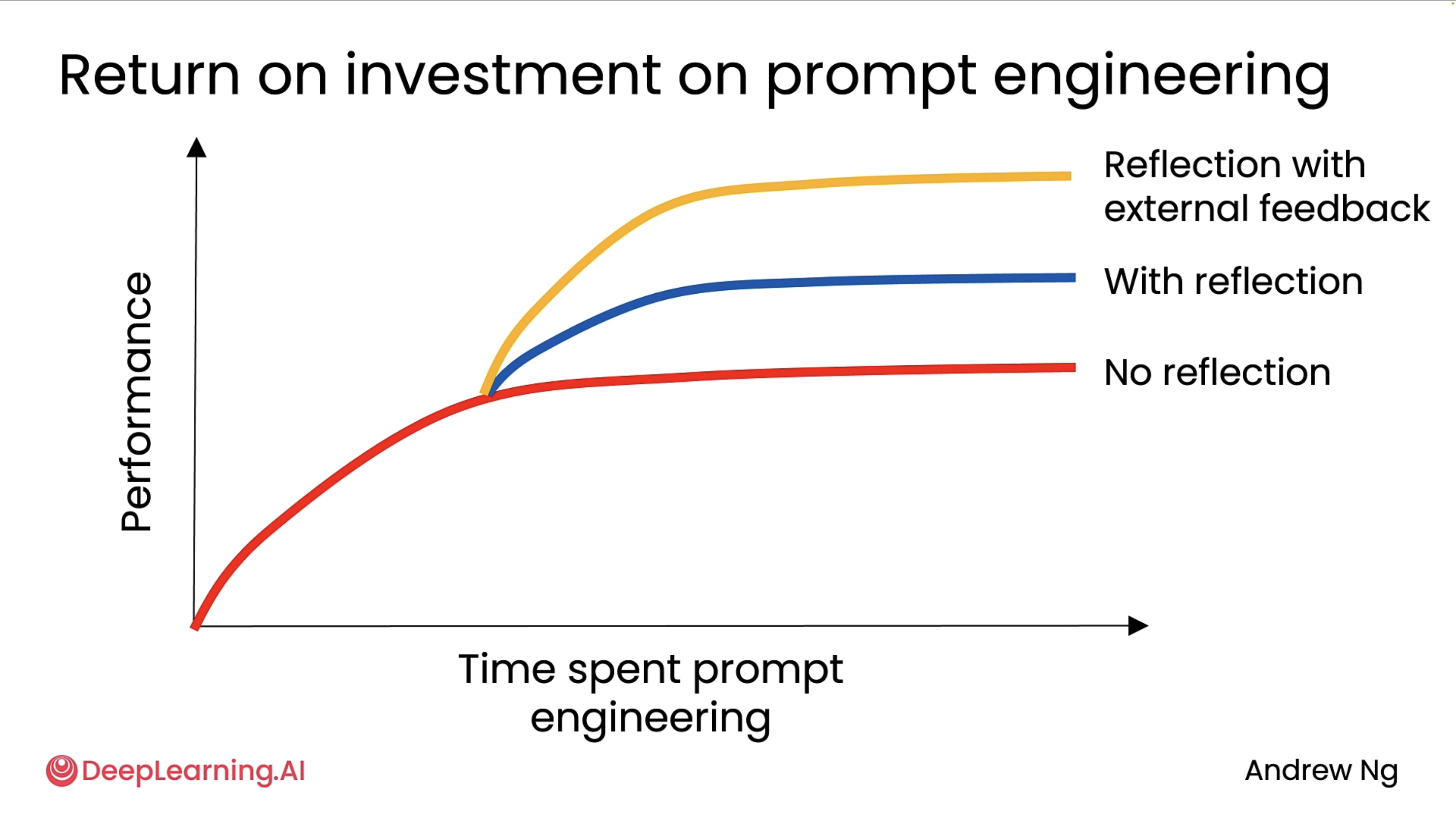
Using external feedback¶
The diagram below should clearly tell you why external feedback is important.
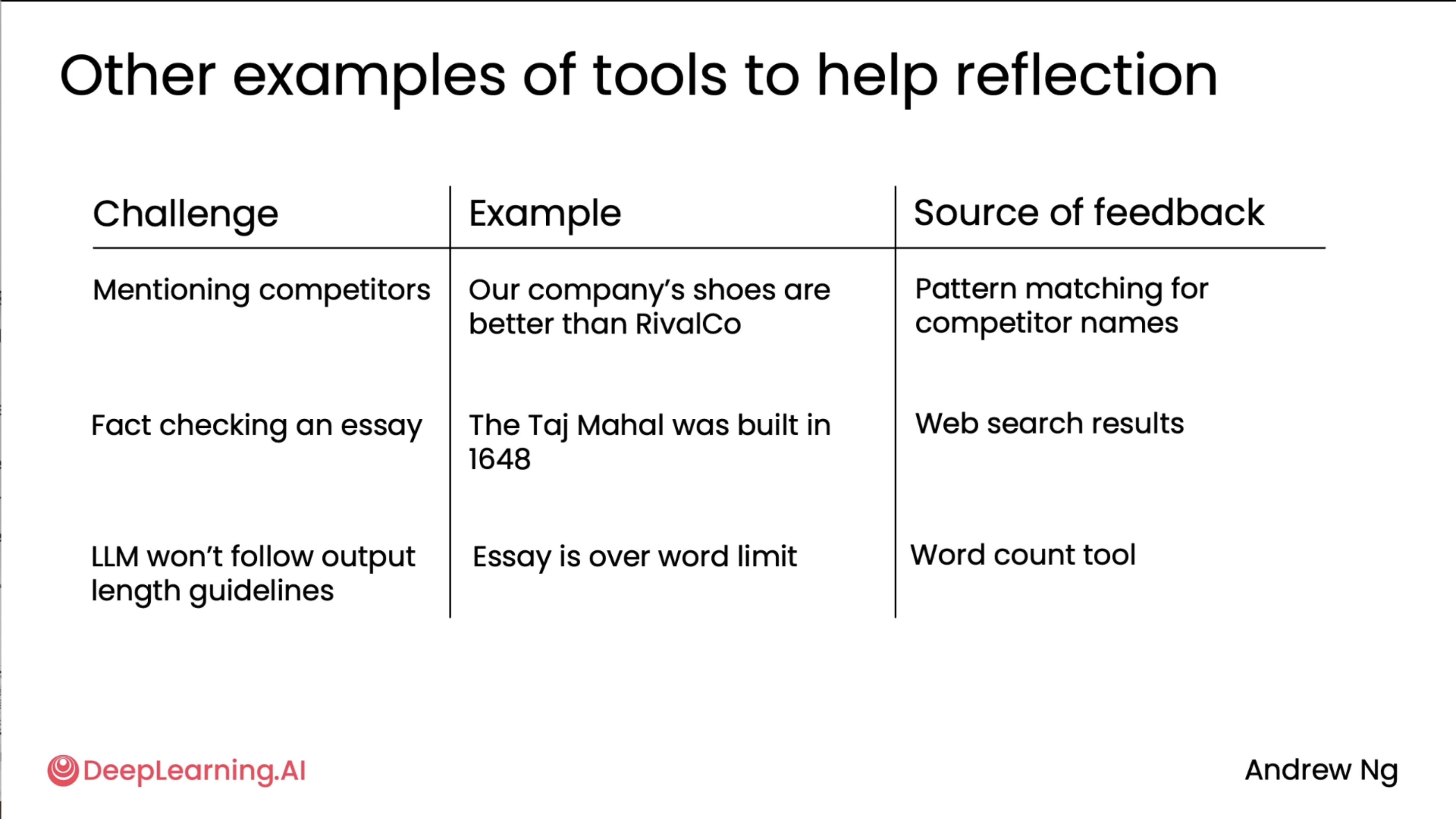
Finally, as we move on to tool calling, the below examples show where tools fit in to provide better results. So, Challenge -> Source of feedback (tool) need to solve it.
Tool Use¶
What are tools?¶
Just as we as humans can do a lot more with tools than we can with just our bare hands, LLMs too can also do a lot more with access to tools. If you were to write a function and give the LLM access to this function, then that lets it respond with a more useful answer. When we let LLMs call functions, or more precisely, let an LLM request to call functions, that's what we mean by tool use, and the tools are just functions that we provide to the LLM that it can request to call.
One important aspect of tool use is, we can leave it up to the LLM to decide whether or not to use any of the tools. Another thing you would notice is that, unlike all of our above examples tools aren't hard coded or fixed to a part of the workflow.
So as a developer, it'll be up to you to think through what are the sorts of things you want an application to really do, and then to create the functions or the tools that are needed to make them available to the LLM to let it use the appropriate tools to complete the sorts of tasks that maybe a restaurant recommender or a retail question answer or a finance assistant may want to do. So depending on your application, you may have to implement and make different tools available to your LLM.
Now, there are also many use cases where you want to make multiple tools or multiple functions available for the LLM for it to choose which of any to call. Like how we see in the following image.

Being able to give your LLM access to tools is a pretty big deal. It will make your applications much more powerful.
Creating a tool¶
Here sensei shows what it would look like if you had to write prompts yourself to tell it when to use tools, and this is what we had to do in an earlier era before LLMs were trained directly to use tools.
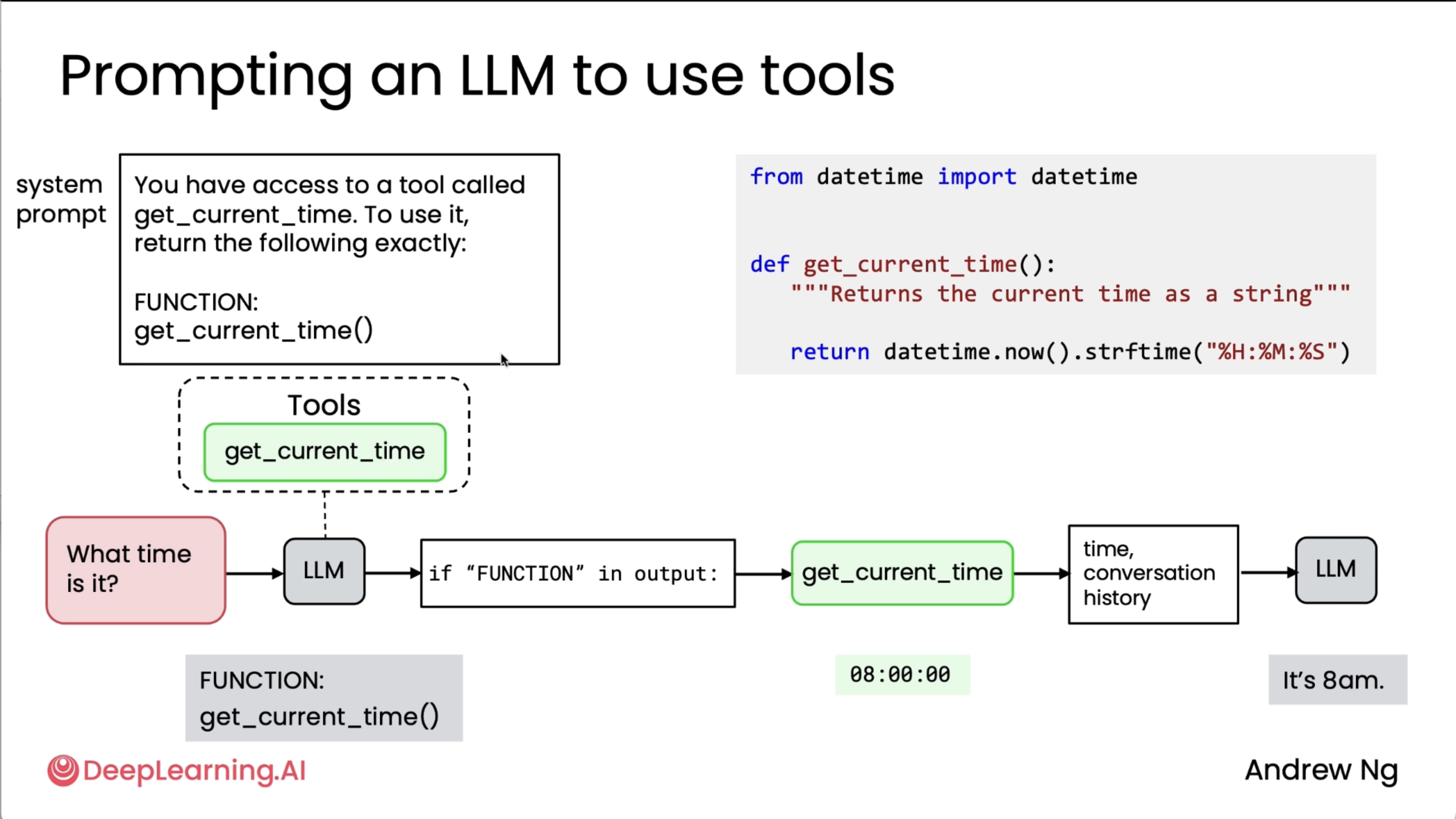
What's happening above: Developer provides function, LLM decides to use it, LLM outputs request, developer’s system executes the function, result fed back to LLM.
To summarize, here's the process for getting LLM to use tools - First, you have to provide the tool to the LLM, implement the function, and then tell the LLM that it is available. When the LLM decides to call a tool, it then generates a specific output that lets you know that you need to call the function for the LLM. Then you call the function, get its output, take the output of the function you just called, and give that output back to the LLM, and the LLM then uses that to go on to whatever it decides to do next, which in our examples in this video was to just generate the final output, but sometimes it may even decide that the next step is to go call yet another tool, and the process continues.
Now, it turns out that this all-caps function syntax is a little bit clunky. This is what we used to do before LLMs were trained natively or to know by themselves how to request that tools be called. With modern LLMs, you don't need to tell it to output all-caps function (this was shown as an example in the video, where the tool function was mentioned after a keyword 'FUNCTION'), then search for all-caps function, and so on. Instead, LLMs are trained to use a specific syntax to request very clearly when it wants a tool called.
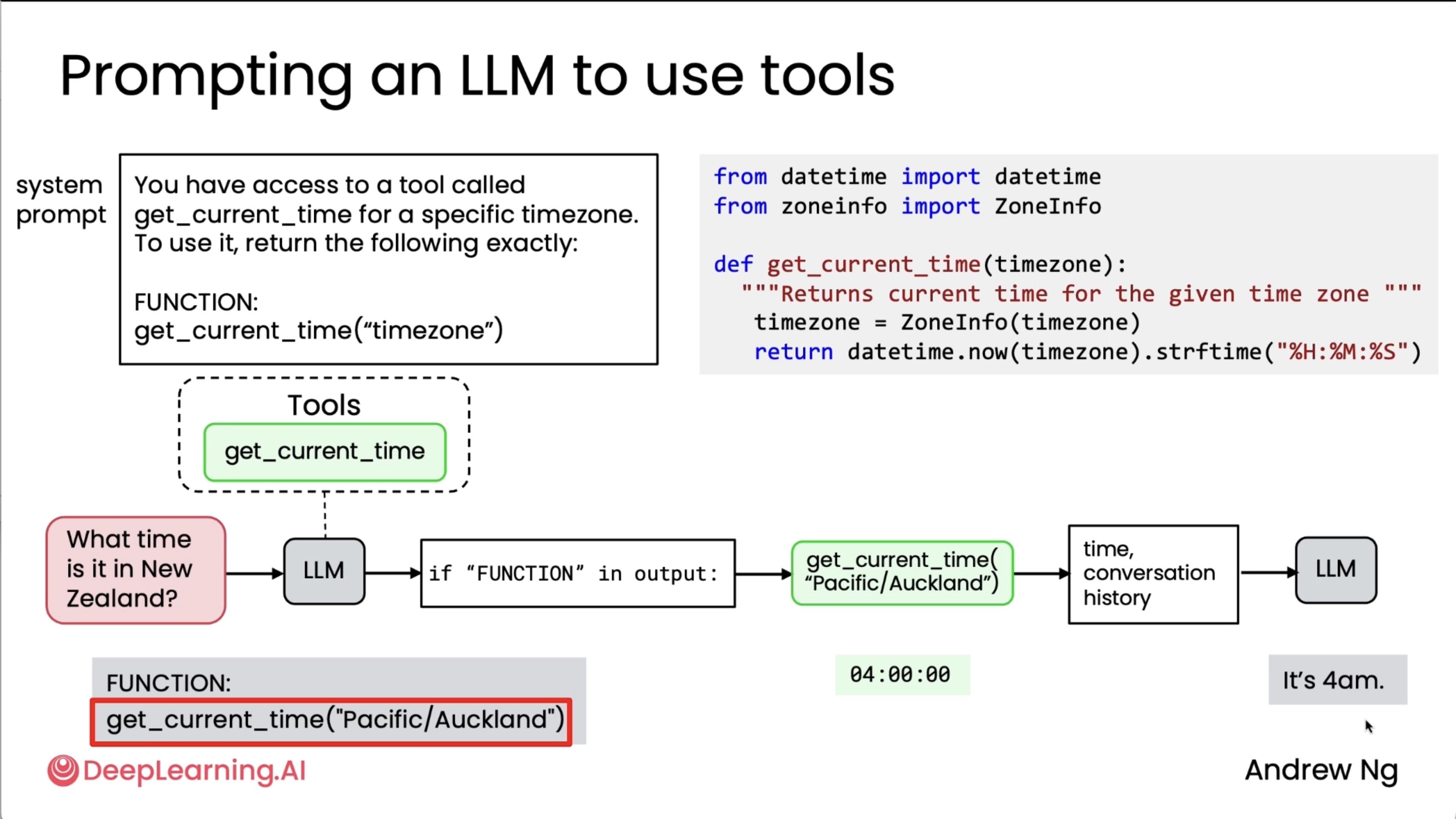
Tool syntax¶
Okay, so here was more about the AISuite library which sensei and his friends had developed, but it still captured the essence of tool calling (my first encounter and implementation of tool calling was via Vercel's AI SDK which is also the core functionality of my AI Persona project - Chat AI).
The following two diagram shows it all.


Also, in the second diagram above I am not really sure how the parameter got its description, sensei only mentioned it got from the "documentation", so I am not really sure how that works here. We will prolly see that in the lab implementations hopefully.
Code implemetations of the graded/ungraded labs for this can be found in the repo mentioned at the start of this blog!
Code execution¶
Okay so I lowkey had a spoiler for this section as I had already learnt about this capability through karpathy sensei in one of his general audience videos. So yes, this is as mind blowing as andrew sensei is telling in the video.
He takes an example of how a simple calculator can be a tool, but in the case of a scientific calculator, instead of making that as a tool, we can ask LLM to execute it as a code instead as it is much easier to calculate exponents via code. And that is what the following two images summarise haha.

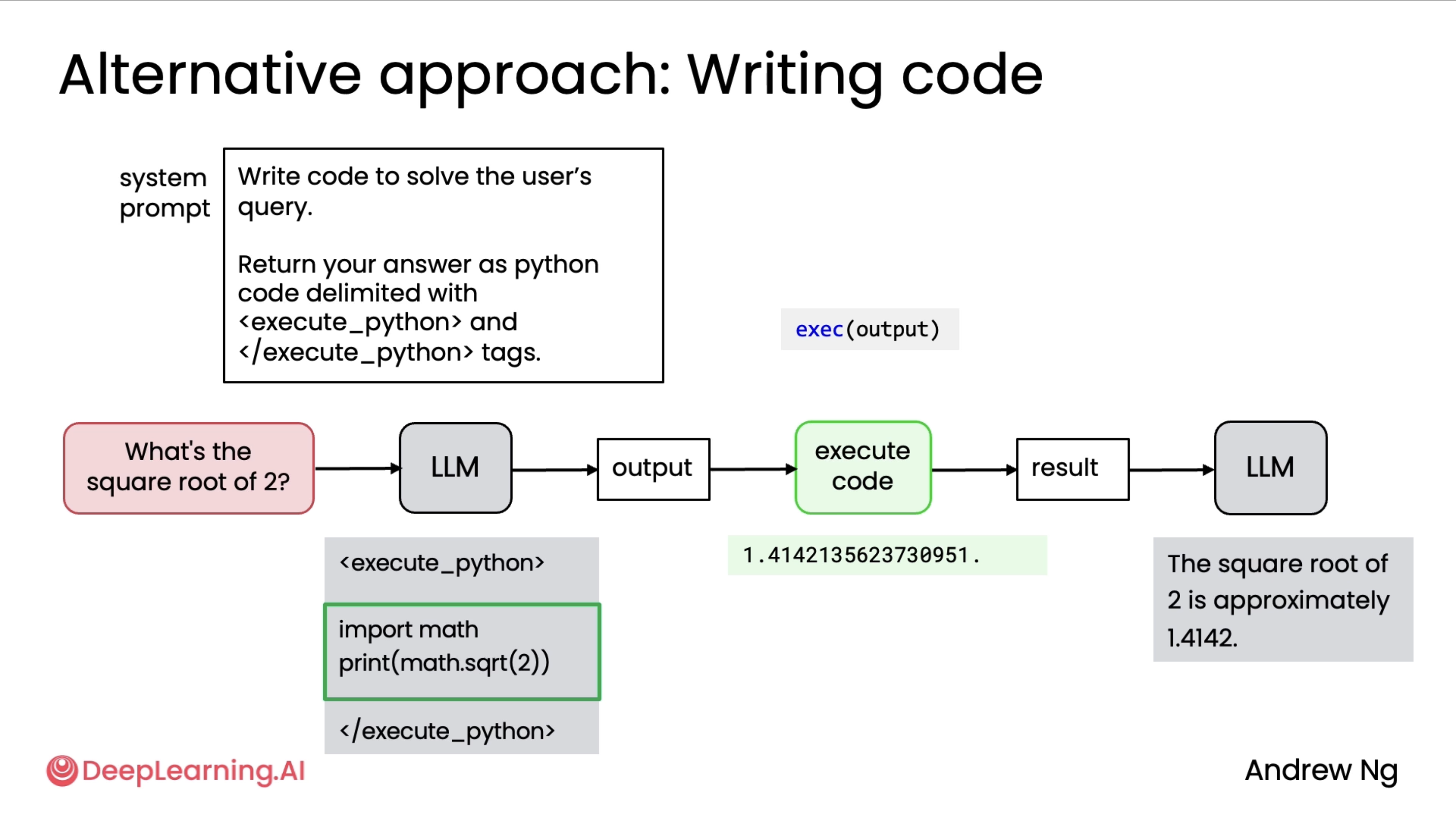
Finally, there was a point where execution of these codes are much safer to be done in a sandbox environment (a similar example to replit where the agent suggested to remove all the python files via rm *.py), some suggested environments were: Docker and E2B. I personally haven't got the chance to use those 2 for code execution specifically, but hopefully I get the chance to soon.
MCP¶
MCP, the Model Context Protocol, was a standard proposed by Anthropic but now adopted by many other companies and by many developers as a way to give an LLM access to more context and to more tools. There are a lot of developers developing around the MCP ecosystem and so learning about this will give you a lot more access to resources for your applications.
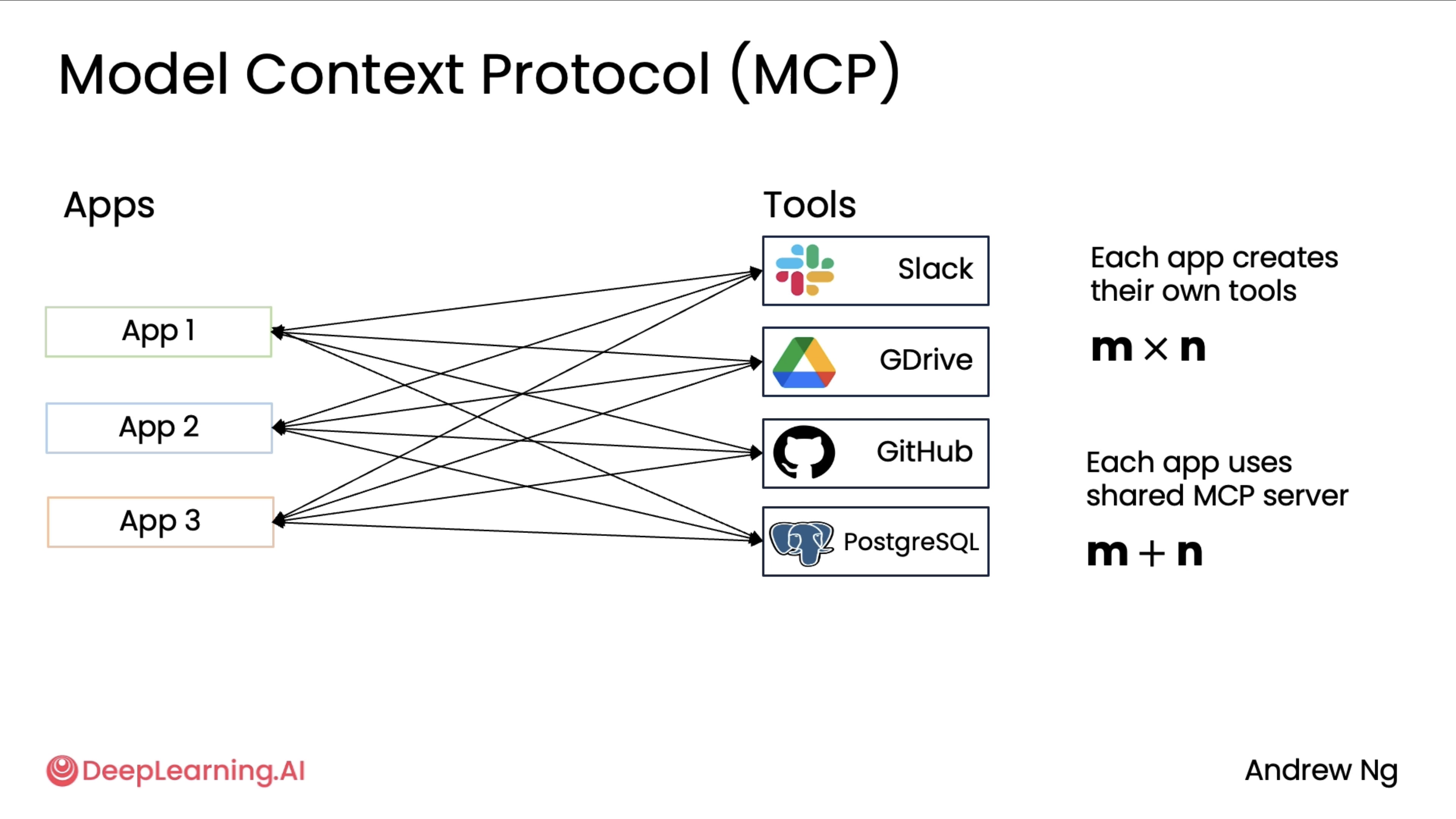
The above diagram shows us the pain points that MCP attempts to solve. If one developer is writing an application that wants to integrate with data from Slack and Google Drive and GitHub or access data from a Postgres database, then they might have to write code to wrap around Slack APIs to have functions to provide to the application, write code to wrap around Google Drive APIs to parse the application, and similarly for these other tools or data sources.
Then what has been happening in the developer community is if a different team is building a different application, then they too will integrate by themselves with Slack and Google Drive and GitHub and so on.
So many developers were all building custom wrappers around these types of data sources. And so if there are M applications being developed and there are N tools out there, the total amount of work done by the community was M times N. What MCP did was propose a standard for applications to get access to tools and data sources so that the total work that needs to be done by the community is now M plus N rather than M times N. The initial design of MCP focused a lot on how to give more context to an LLM or how to fetch data. So a lot of the initial tools were ones that would just fetch data. And if you read the MCP documentation, that refers to these asresources. But MCP gives access to both data as well as the more general functions that an application may want to call.
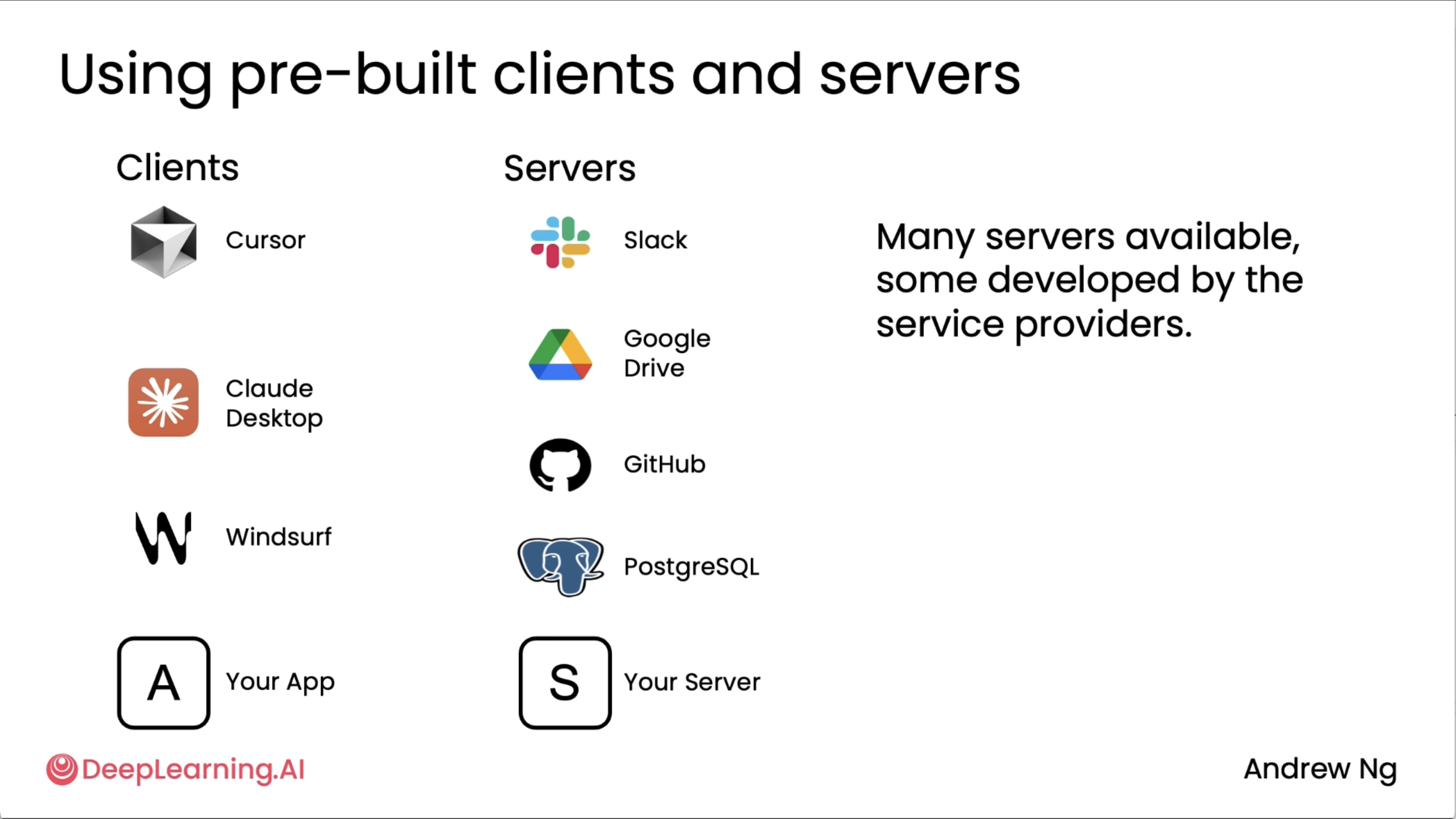
As you can see in the above diagram, It turns out that there are many MCP clients. These are the applications that want access to tools or to data as well as service, which are often the software wrappers that then give access to data in Slack or GitHub or Google Drive or allows you to take actions at these different types of resources. So today there's a rapidly growing list of MCP clients that consume the tools or the resources as well as MCP service that provide the tools and the resources. And I hope that you find it useful to build your own MCP client. Your application maybe one day will be an MCP client. And if you want to provide resources to other developers, maybe you can build your own MCP server someday.
I also loved the example sensei showed on how he used Claude desktop (client) to ask questions on his repos on github (server) like explain the project or what were the last set of PRs. Prolly the simplest example I have seen, shown very well. A detailed breakdown on MCP can be found on my other blog post which was also by DeepLearning.AI!
Practical tips for building Agentic AI¶
"It turns out that one of the things I've seen that distinguishes people that can execute agentic workflows really well versus teams that are not as efficient at it is your ability to drive a disciplined evaluation process."
Evaluations (evals)¶
When developing an agentic AI system, it's difficult to know in advance where it will work and where it won't work so well, and thus where you should focus your effort. So very common advice is to try to build even a quick and dirty system to start, so you can then try it out and look at it to see where it may not yet be working as well as you wish, to then have much more focused efforts to develop it even further. In contrast, I find that it's sometimes less useful to sit around for too many weeks theorizing and hypothesizing how to build it. It's often better to just build a quick system in a safe, reasonable way that doesn't leak data, kind of do it in a responsible way, but just build something quickly so you can look at it and then use that initial prototype to prioritize and try further development.

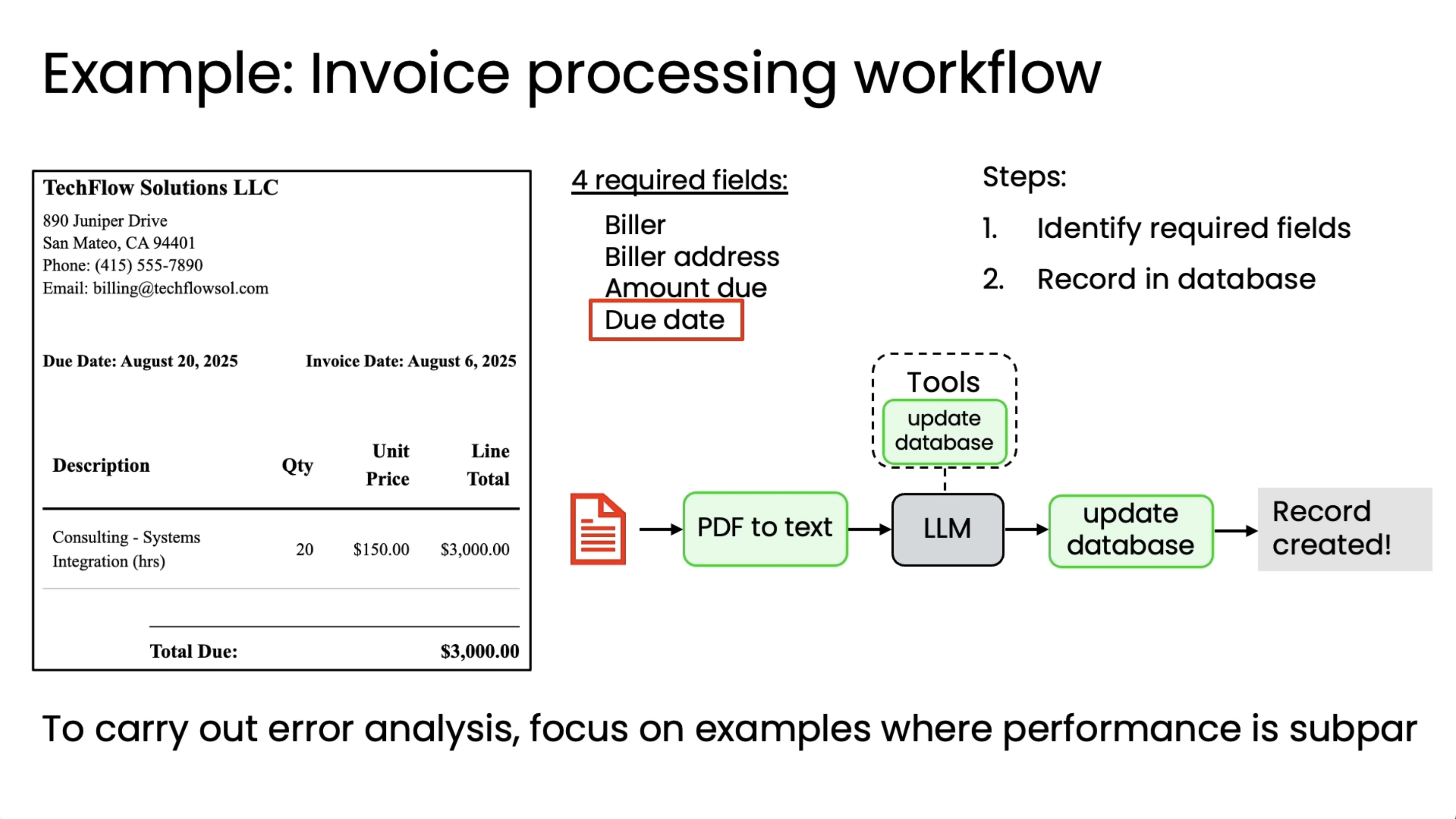
In the above diagram's case, you might conclude that one common error mode is that it is struggling with the dates. In that case, one thing you might consider would be to of course figure out how to improve your system to make it extract due dates better, but also maybe write an eval to measure the accuracy with which it is extracting due dates.
So one of the reasons why building a quick and dirty system and looking at the output is so helpful is it even helps you decide what do you want to put the most effort into evaluating.
So this is what improving an Agentic AI workflow will often feel like. Look at the output, see what's wrong, then if you know how to fix it, just fix it. But if you need a longer process of improving it, then put in place an eval and use that to drive further development.
One other thing to consider is if after working for a while, if you think those 20 examples (as seen in the above diagram) you had initially aren't good enough, maybe they don't cover all the cases you want, or maybe 20 examples is just too few, then you can always add to the eval set over time to make sure it better reflects your personal judgments on whether or not the system's performance is sufficiently satisfactory. This is just one example.
In order to think about how to build evals for your application, the evals you build will often have to reflect whatever you see or you're worried about going wrong in your application. And it turns out that broadly, there are two axes of evaluation.
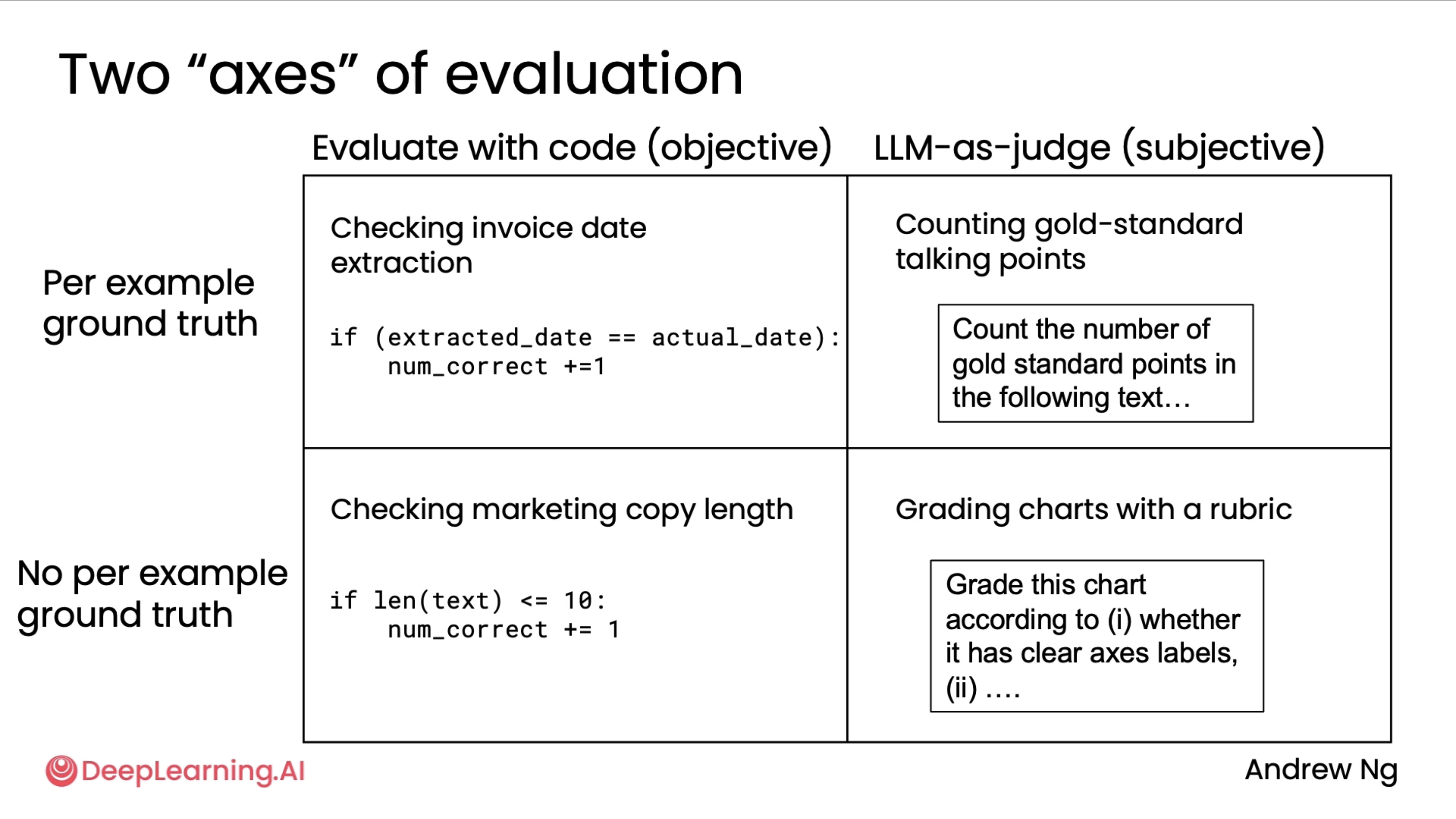
As seen in the above diagram, it turns out that broadly, there are two axes of evaluation. On the top axis is the way you evaluate the output. In some cases, you evaluate it by writing code with objective evals, and sometimes you use an LLM-as-a-judge for more subjective evals. On the other axis is whether you have a per-example ground truth or not. So for checking invoice date extraction, we were writing code to evaluate if we got the actual date, and that had a per-example ground truth because each invoice has a different actual date. But in the example where we checked marketing copy length, every example had a length limit of 10, and so there was no per-example ground truth for that problem. In contrast, for counting gold standard talking points, there was a per-example ground truth because each article had different important talking points. But we used an LLM-as-a-judge to read the essay to see if those topics were adequately mentioned because there's so many different ways to mention the talking points. And the last of the four quadrants would be LLM-as-a-judge with no per-example ground truth. And one place where we saw that was if you are grading charts with a rubric. This is when we're looking at visualizing the coffee machine sales, and if you ask it to create a chart according to a rubric, such as whether it's clear access labels and so on, there is the same rubric for every chart, and that would be using an LLM-as-a-judge but without a per-example ground truth.
And by the way, those are sometimes also called end-to-end evals because one end is the input end, which is the user query prompt, and the other end is the final output. And so all of these are evals for the entire end-to-end system's performance.
Finally, some quick tips on this.

Error Analysis and Prioritizing next steps¶
Let's say you've built an agentic workflow and if it's not yet working as well as you wish, the question is where do you focus your efforts to make it better? Turns out agentic workflows have many different components and working on some of the components could be much more fruitful than working on some other components. So your skill at choosing where to focus your efforts makes a huge difference in the speed with which you can make improvements to your system. And I found that one of the biggest predictors for how efficient and how good a team is, is whether or not they're able to drive a disciplined error analysis process to tell you where to focus your efforts. So this is an important skill.
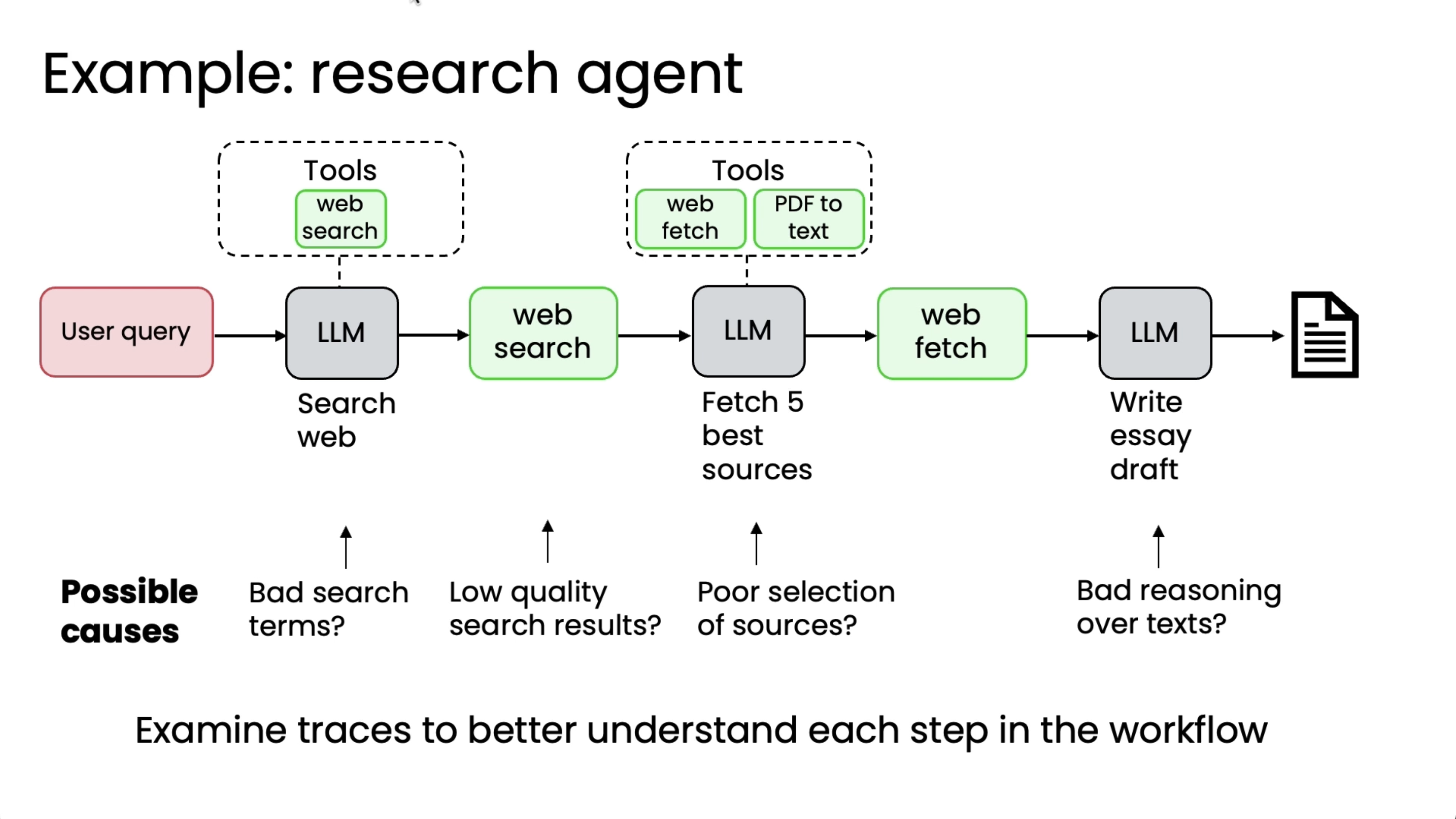
So it turns out that there are teams that sometimes look at this and go by gut to pick one of these components to work on and sometimes that works and sometimes that leads to many months of work with very little progress in the overall performance of the system. So rather than going by gut to decide which of these many components to work on, I think it's much better to carry out an error analysis to better understand each step in the workflow. And in particular, I'll often examine the traces and that means the intermediate output after each step in order to understand which component's performance is subpar, meaning say much worse than what a human expert would do, because that points to where there may be room for security improvement.
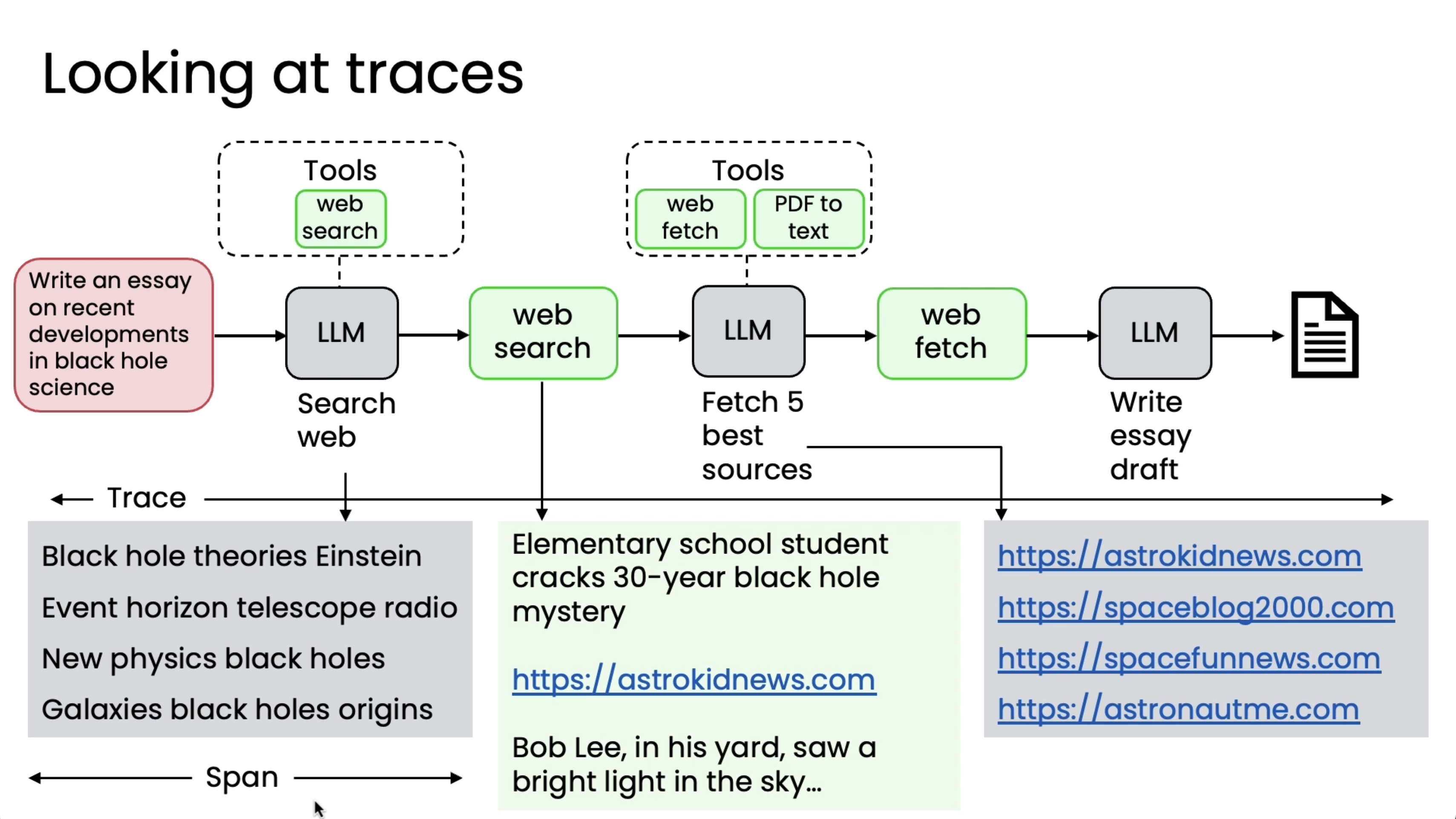
To introduce some terminology, the overall set of outputs of all of the intermediate steps is often called the trace of a run of this agent. And then some terminology you see in other sources as well is the output of a single step is sometimes called a span (This is terminology from the computer observability literature where people try to figure out what computers are doing).
Below is a table diagram of how error analysis debugging is done to focus on which component to focus on for improving first.
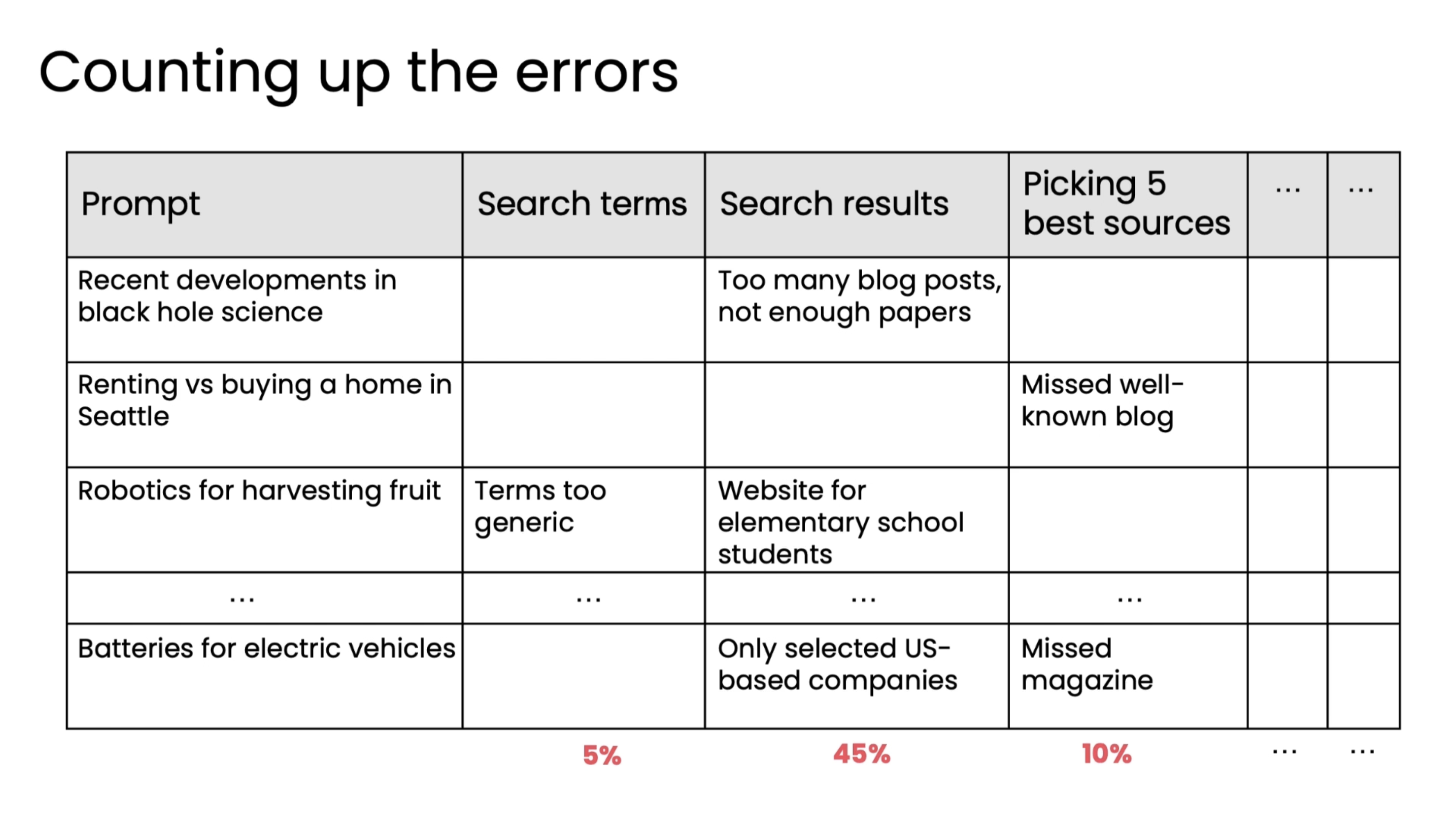
And some tips for error analysis.

More Error Analysis examples¶
In the previous section, we saw how we can perform error analysis in the research agent example. Here, we will look at a few more. As for many developers, it's only by seeing multiple examples that you can then get practice and hone your intuitions about how to carry out error analysis.
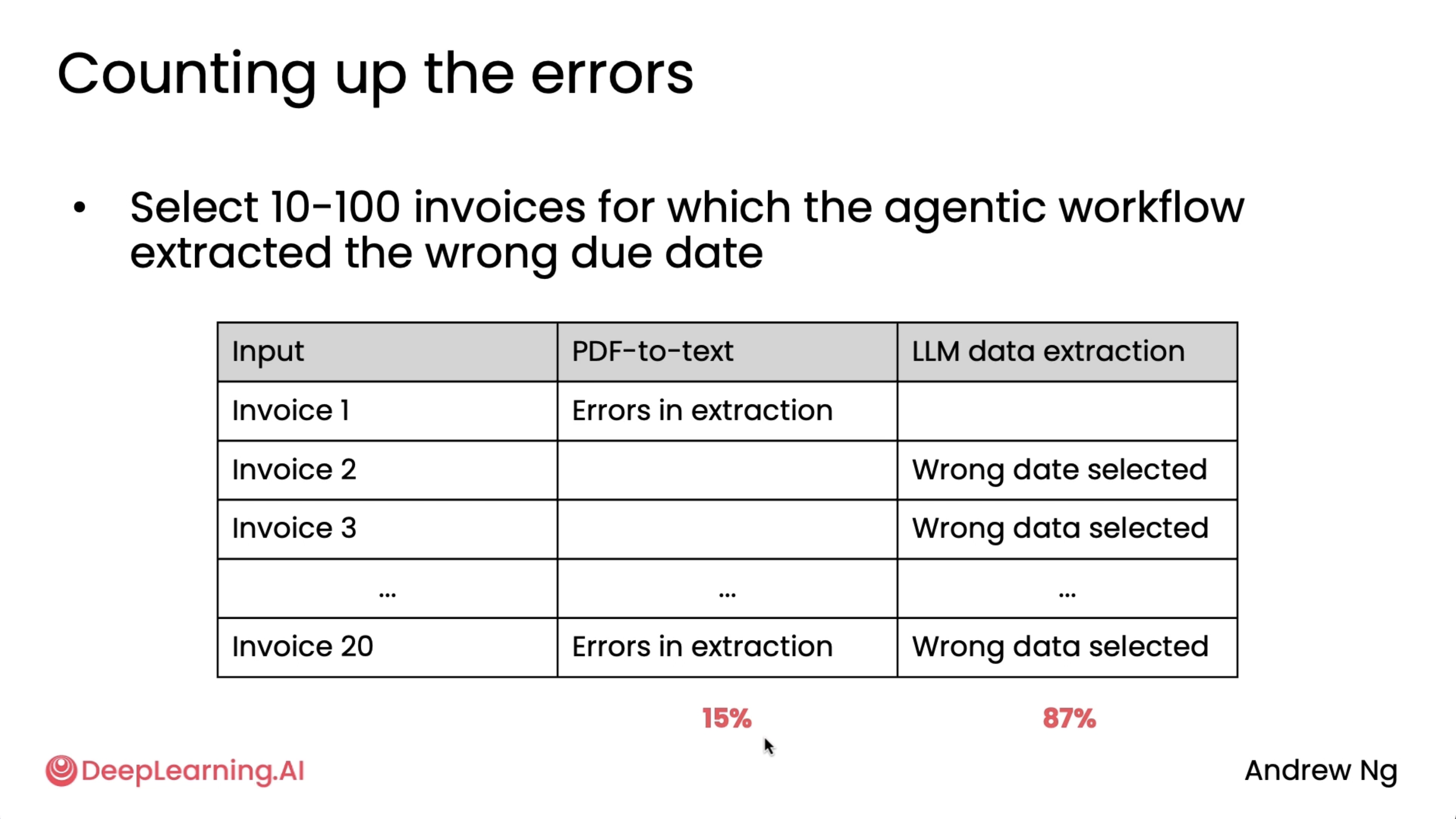
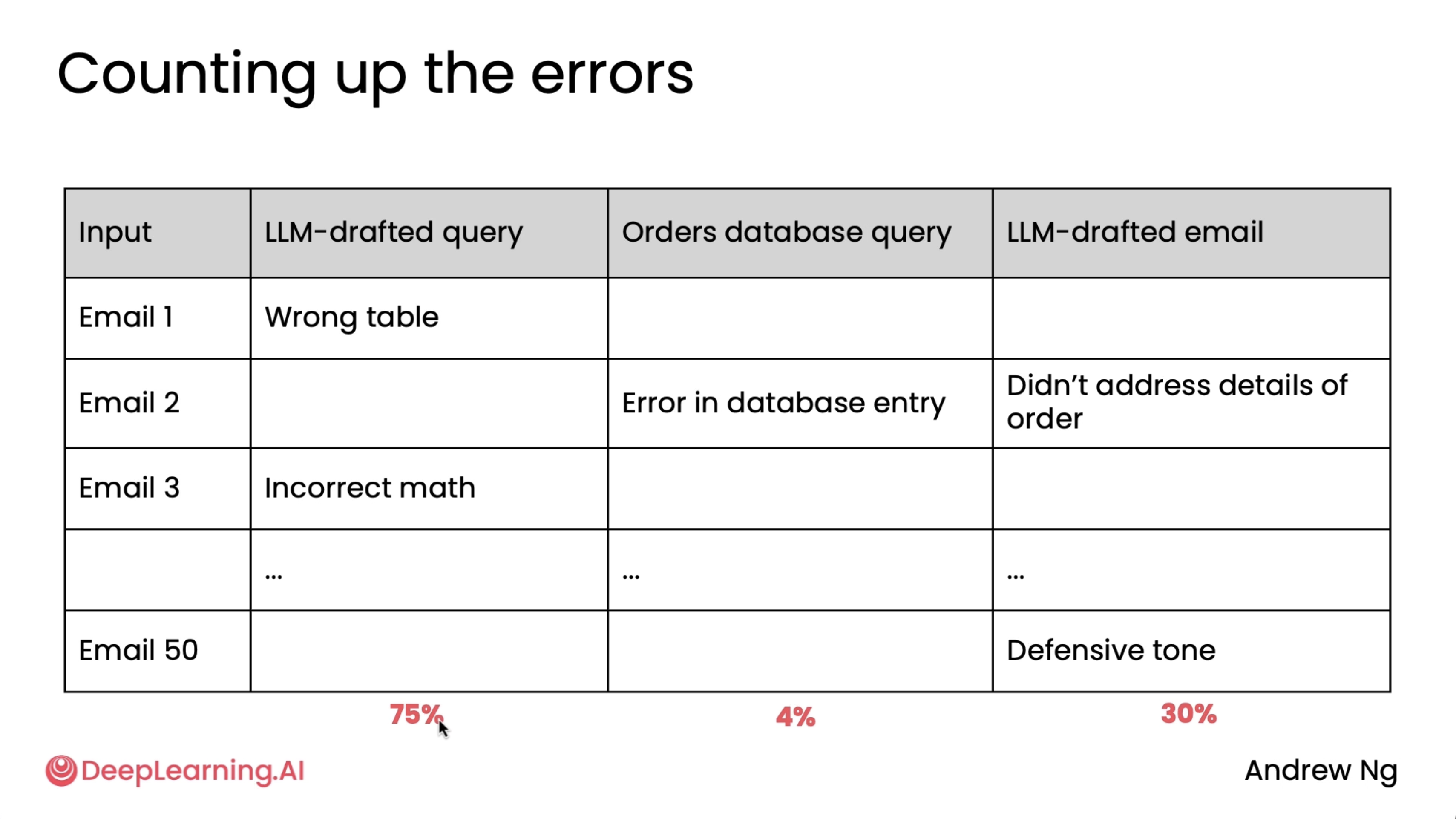
Other two examples are invoice processing and responding to customer emails. Also, the percentages in the respective second images will not add up to 100% because the errors are not mutually exclusive.
Invoicing error analysis:
Customer email analysis:

Next, we will see how instead of doing end-to-end analysis of the entire system, how we can do a component based one.
Component-level evaluations¶
Let's take a look at how to build and use component-level evals. In our example of a research agent, we said that the research agent was sometimes missing key points. But if the problem was web search, if every time we change the web search engine, we need to rerun the entire workflow, that can give us a good metric for performance, but that type of eval is expensive. Moreover, this is a pretty complicated workflow, so even if web search made things a little bit better, maybe noise introduced by the randomness of other components would make it harder to see little improvements to the web search quality.
So as an alternative to only using end-to-end evals, what I would do is consider building an eval just to measure the quality of the web search component. For example, to measure the quality of the web search results, you might create a list of gold standard web resources. So for a handful of queries, have an expert say, these are the most authoritative sources that if someone was searching the internet, they really should find these web pages or any of these web pages would be good.

And then you can write code to capture how many of the web search outputs correspond to the gold standard web resources. The standard metrics from information retrieval, the F1 score, but there are standard metrics that allow you to measure of a list of web pages returned by web search, how much does that overlap with what an expert determined are the gold standard web resources. With this, you're now armed with a way to evaluate just the quality of the web search component.
And so as you vary the parameters or hyperparameters of how you care about web search, such as if you swap in and out different web search engines, so maybe try Google and Bing and Dr. Go and Tivoli and U.com and others, or as you vary the number of results or as you vary the date range that you ask the web search engines to search over, this can very quickly let you judge if the quality of the web search component is going up and does make more incremental improvements. And then of course, before you call the job done, it would be good to run an end-to-end eval to make sure that after tuning your web search system for a while that you are improving the overall system performance.
But during that process of tuning these hyperparameters one at a time, you could do so much more efficiently by evaluating just one component rather than needing to rerun end-to-end evals every single time.
So component level evals can provide a clearer signal for specific errors. It actually lets you know if you're improving the web search component or whatever component you're working on and avoid the noise in the complexity of the overall end-to-end system. And if you're working on a project where you have different teams focused on different components, it can also be more efficient for one team to just have his own very clear metric to optimize without needing to worry about all of the other components. And so this lets the team work on a smaller, more targeted problem faster. So when you've decided to work on improving a component, consider if it's worth putting in place a component-wise eval and if that will let you go faster on improving the performance of that component.

Now the one thing you may be wondering is, if you decided to improve a component, how do you actually go about making that one component work better?
How to address problems you identify¶
An agentic workflow may comprise many different types of components, and so your tools for improving different components will be pretty different.
For the component which is non-LLM dependant:

For LLM based component (Here keep fine tuning as the very last resort as its too expensive to implement. Rather focus on improving your intuition on which model among the pool of models perform best for respective tasks):

Smaller models (~8b range types) are maybe not as good as the larger ones in following instructions. But its better to label that different models are better for different tasks.
Next would be to keep reading other peoples prompts to see what works and why (after having learnt the art of structuring your prompt).
Latency, cost optimization¶
When you start developing, usually the number one thing to worry about is just are the outputs sufficiently high quality. But then when the system is working well and you put in the production, then there's often value to make it run faster as well as run at lower cost as well. Here is where latency and cost optimization comes in (and personally I have always found this to be a HUGE deal breaker at the end).
For latency, Time the workflow for each step.
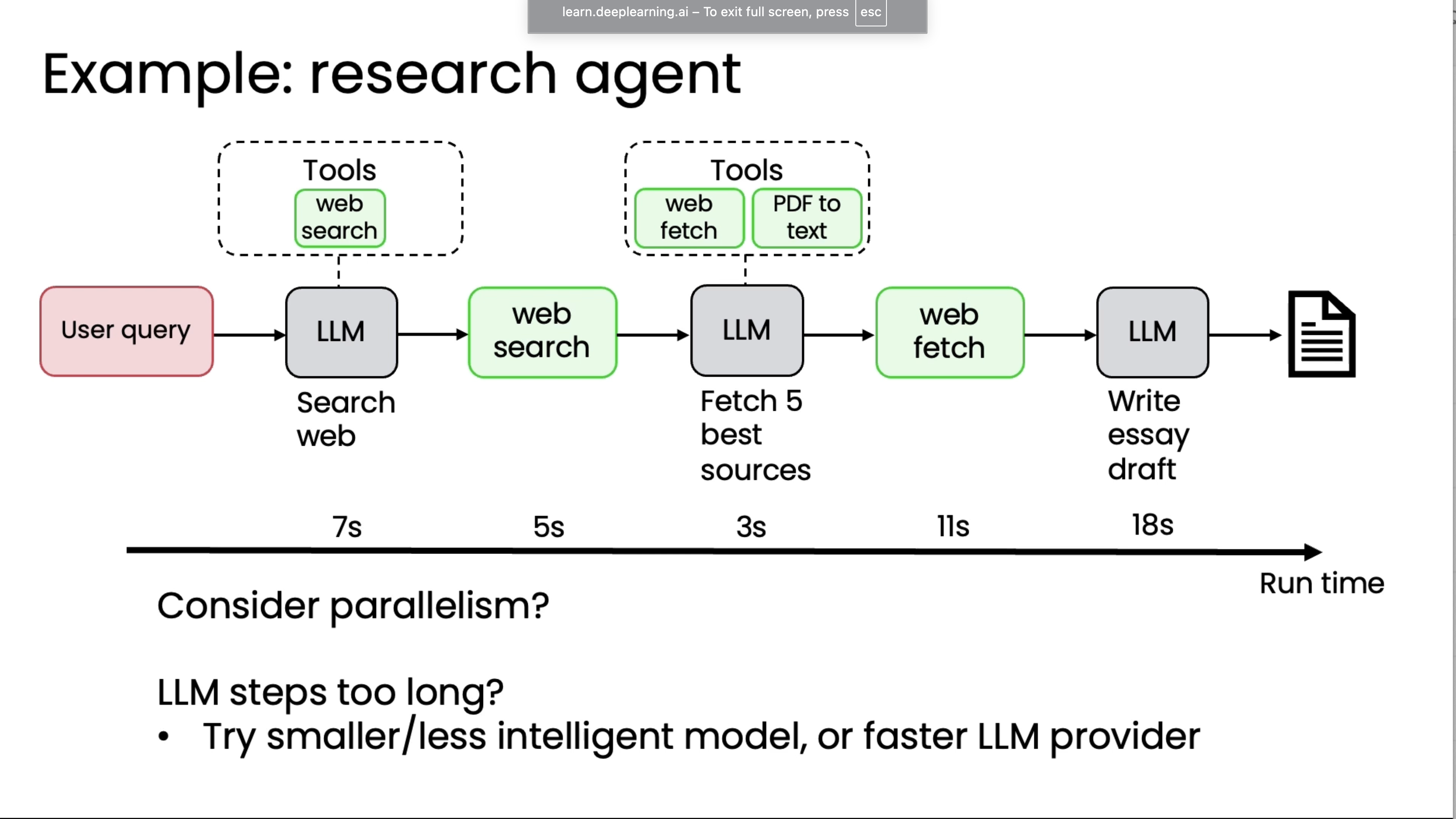
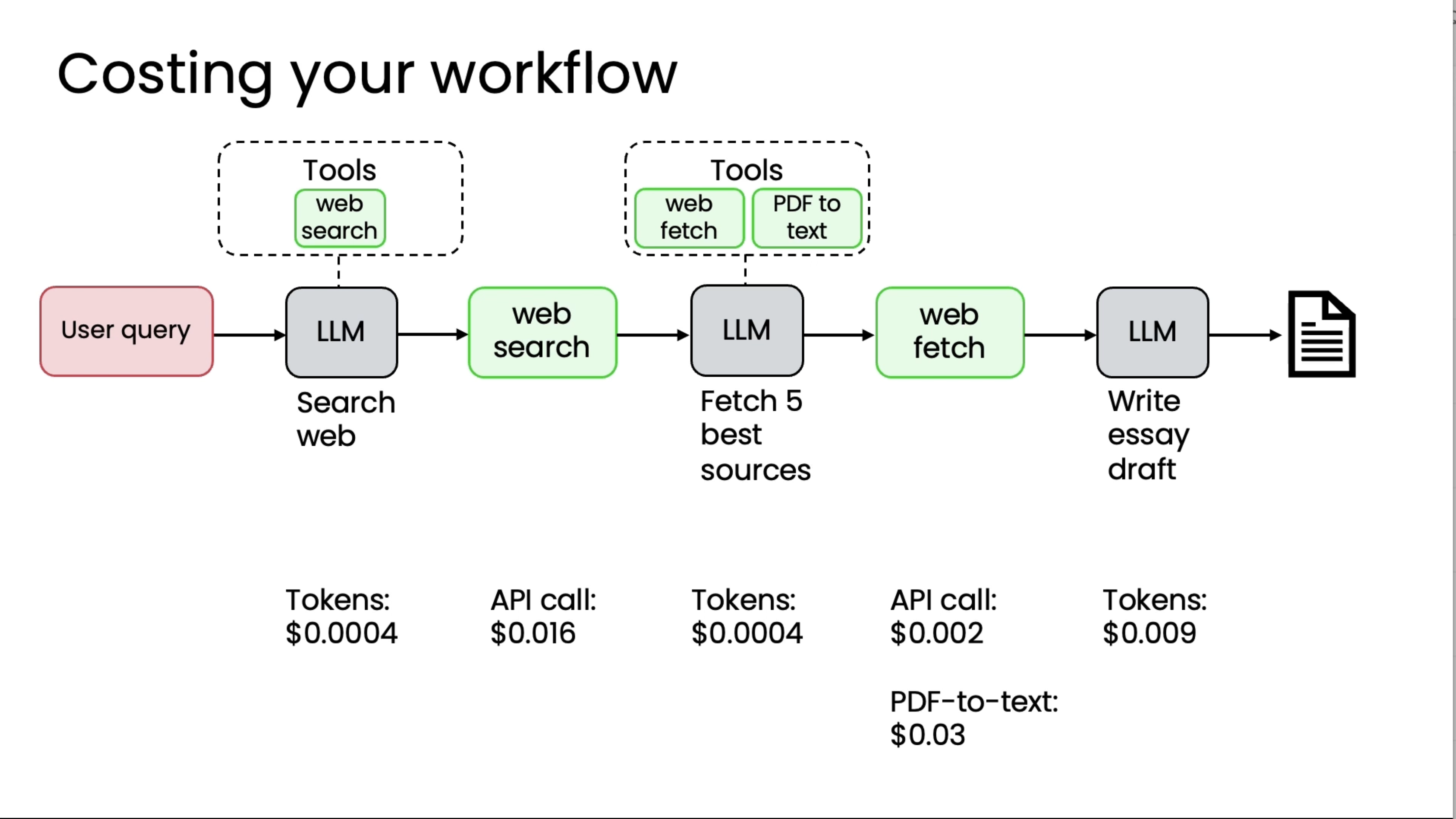
For cost optimization, Cost per tokens check for each step.
Development process summary¶
We've seen mainly tips in this module, now lets just have a quick look at how this entire process looks like while going through it.
When we're building these workflows, there are two major activities where we often spending time on. One is building, so writing software, trying to write code to improve my system. And the second, which sometimes doesn't feel like progress, but is equally important, is analysis to help me decide where to focus my build efforts next. And we often go back and forth between building and analyzing, including things like error analysis.
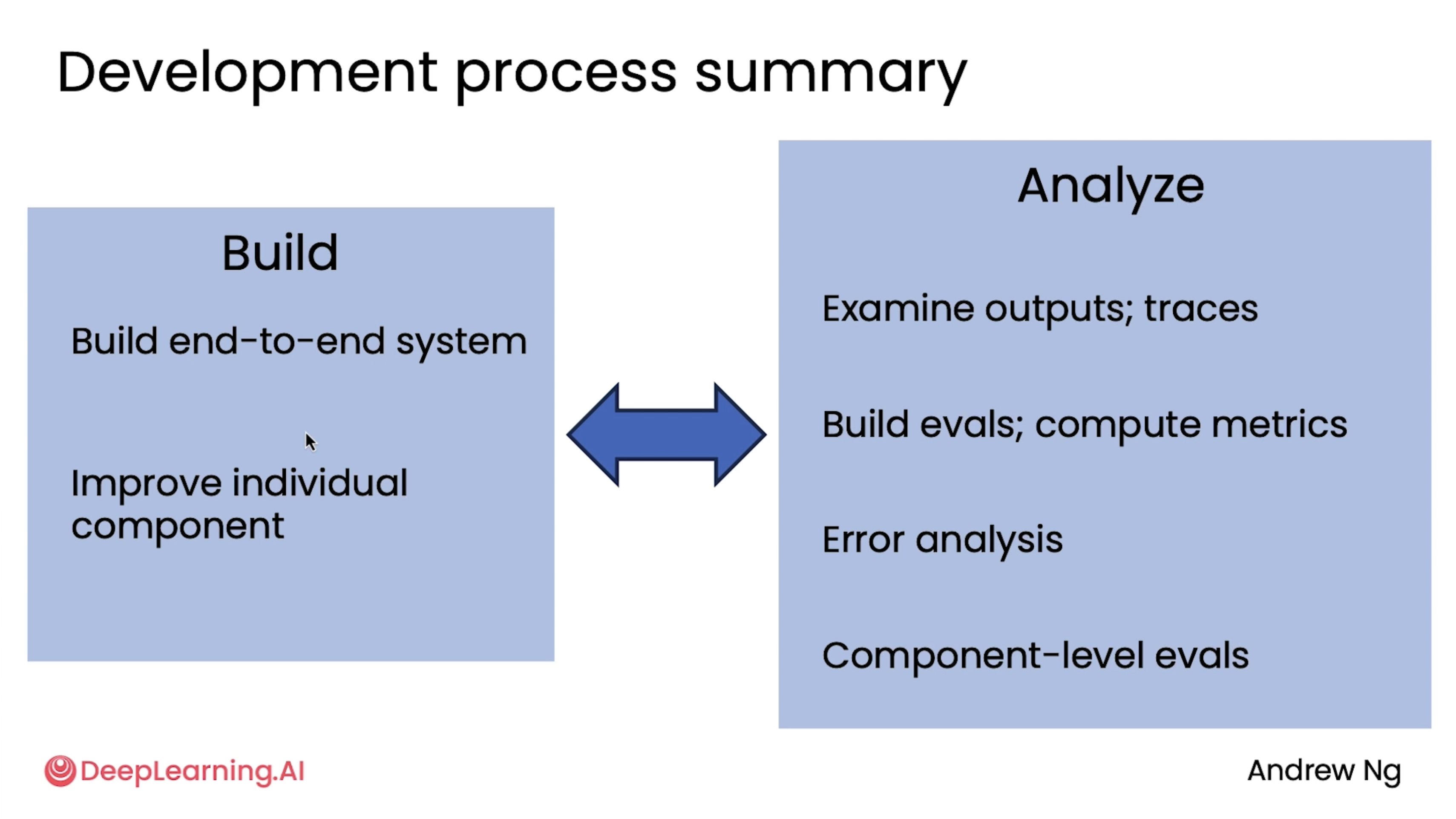
So the workflow of building an agentic system often goes back and forth. It's not a linear process. We sometimes tune the end-to-end system, then do some error analysis, then improve a component for a bit, then tune the component-level evals.
Code implemetations of the ungraded labs for this can be found in the repo mentioned at the start of this blog! There was no graded lab for this.
Patterns for Highly Autonomous Agents¶
This section I felt was highly illustrative so I have added the slides which I thought would be essential and relavent during revision. I have added necessary points wherever necessary as well.
Planning workflows¶
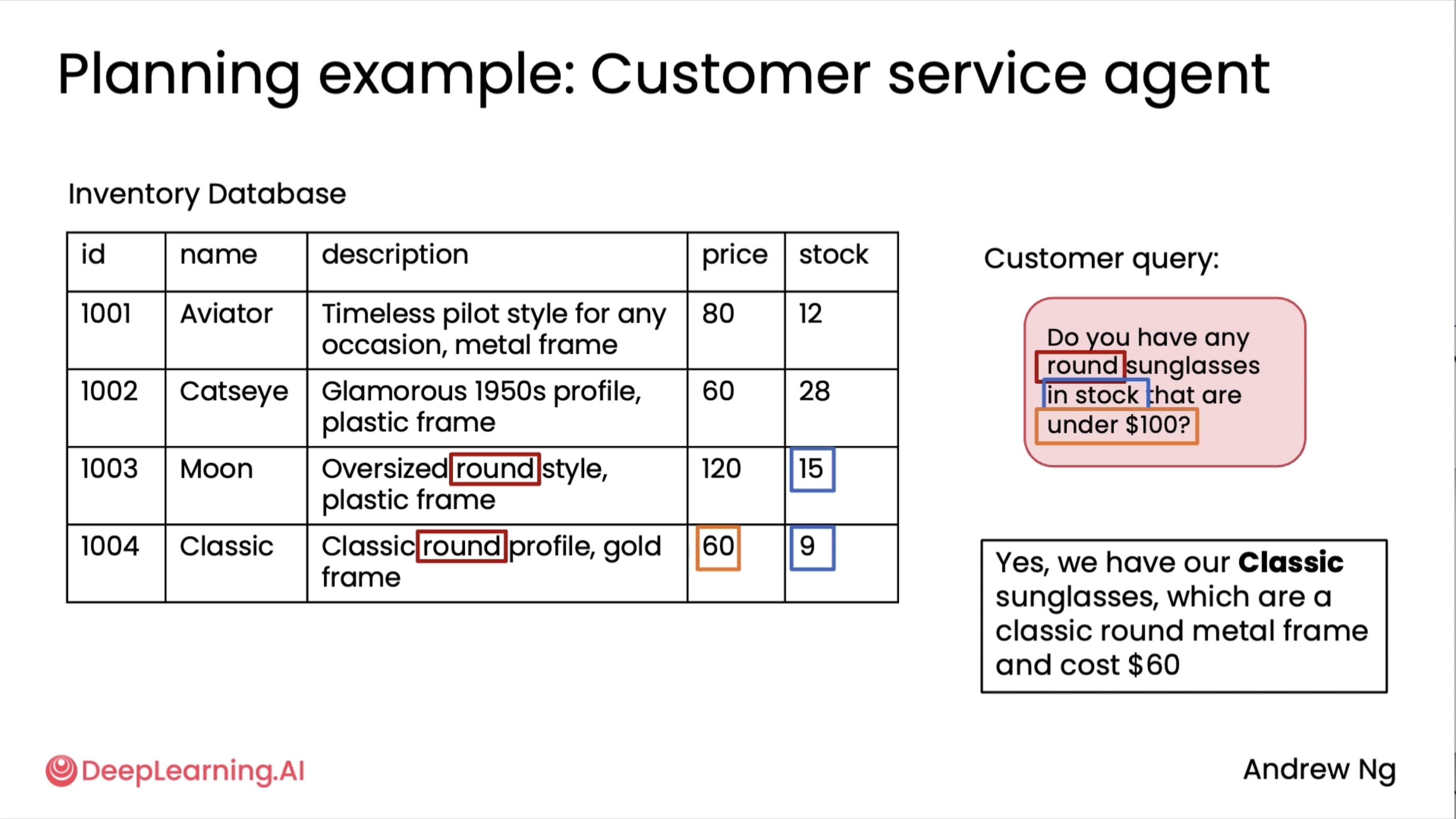
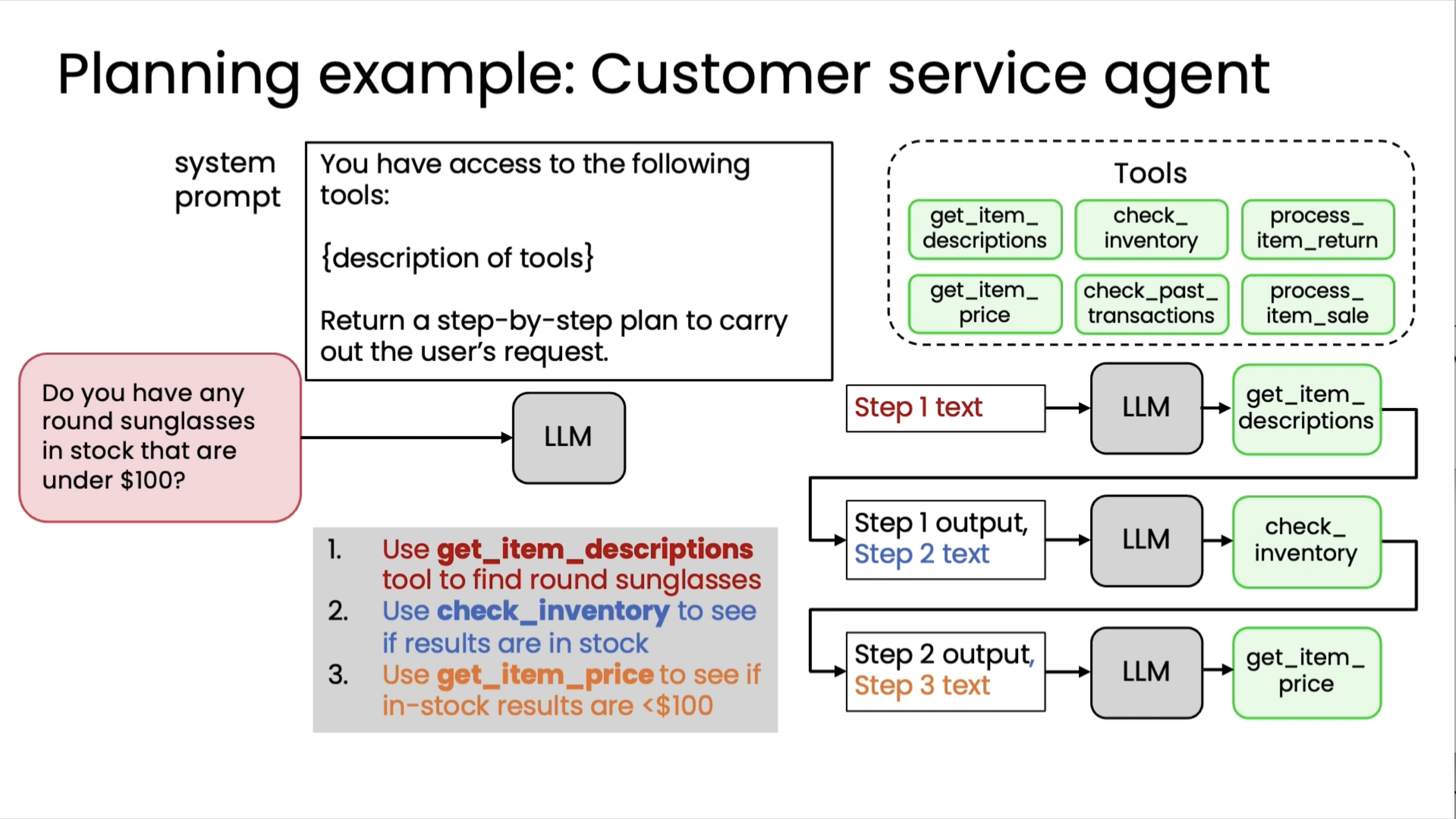
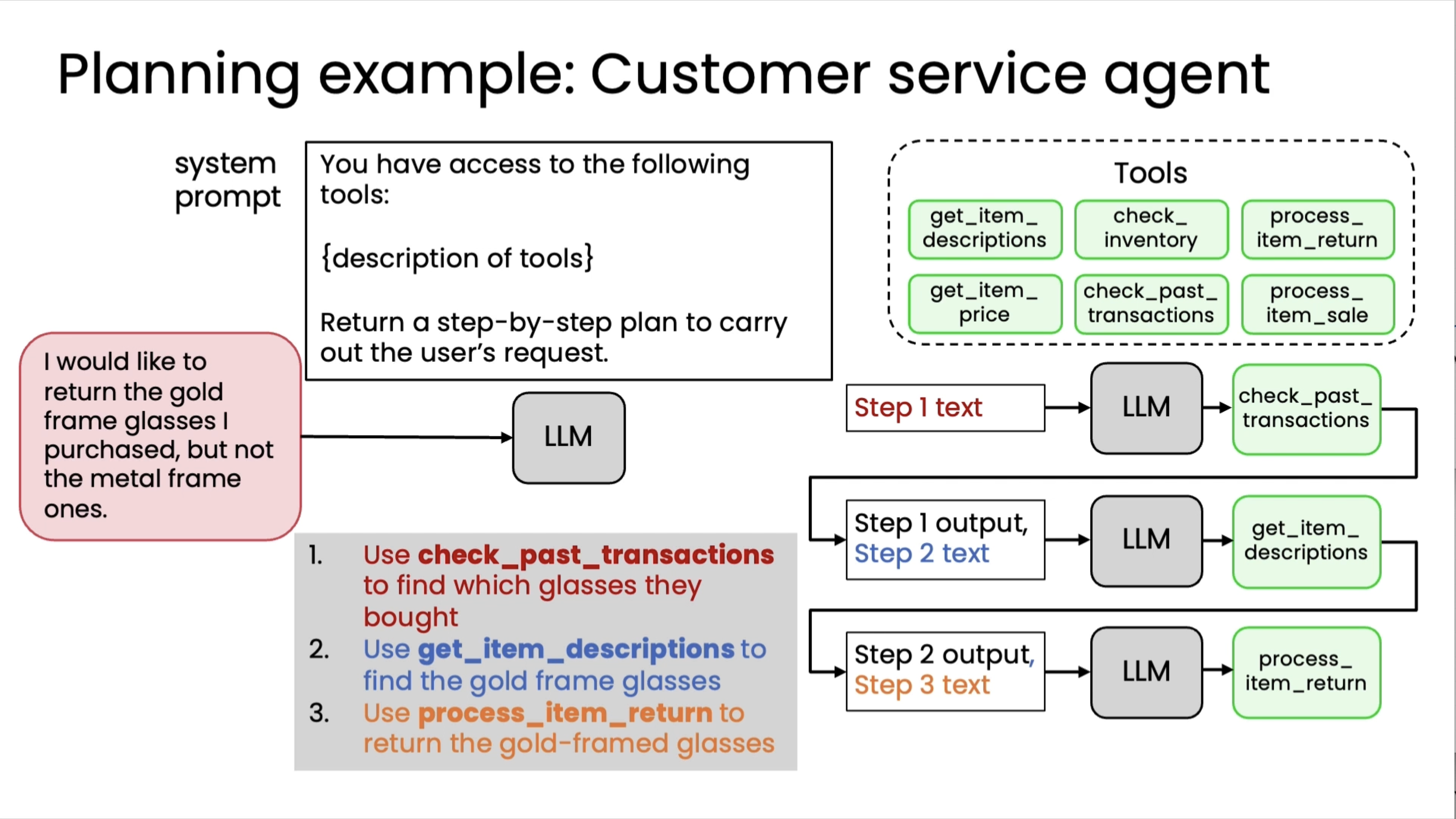
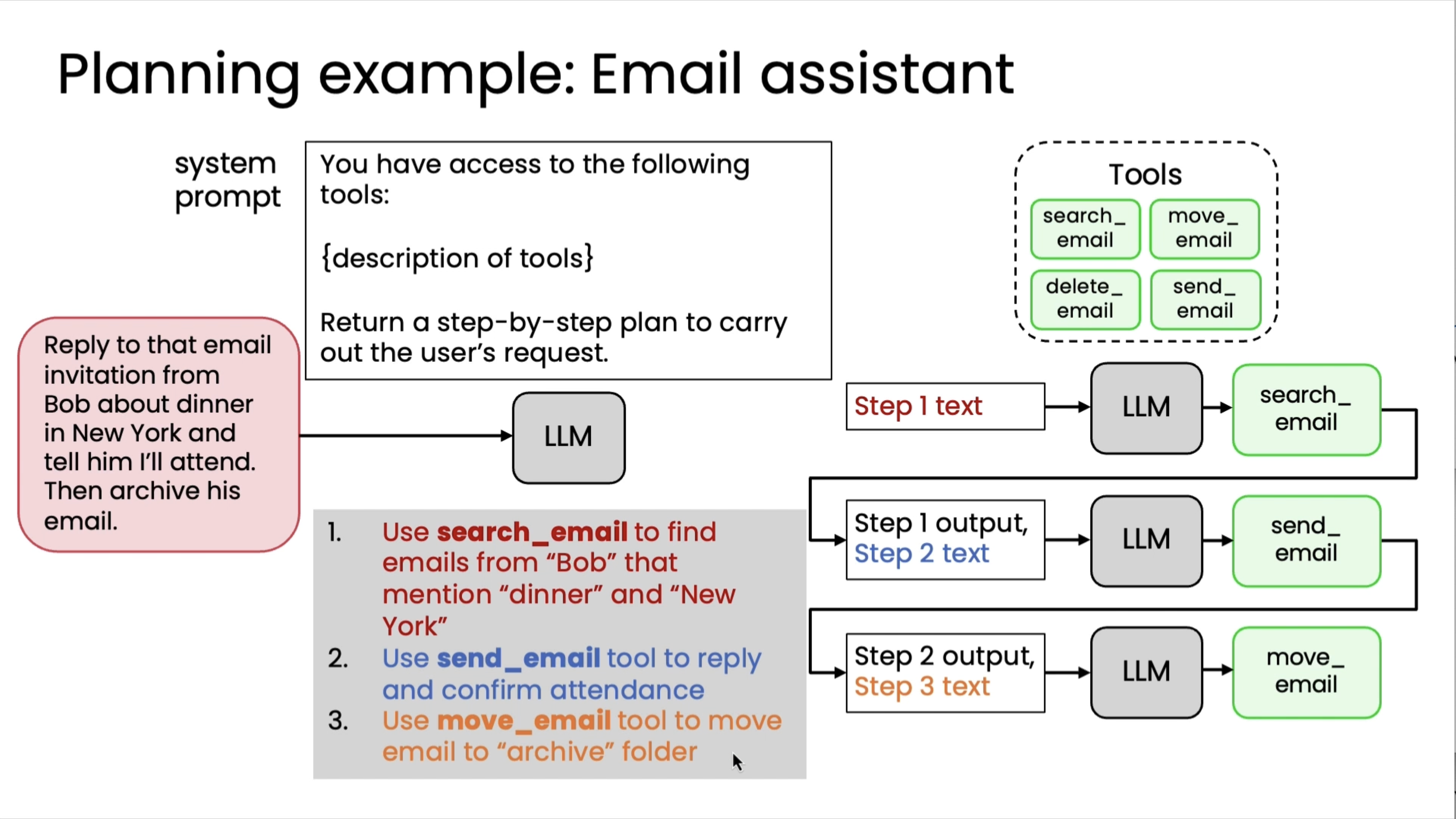
Creating and executing LLM plans¶
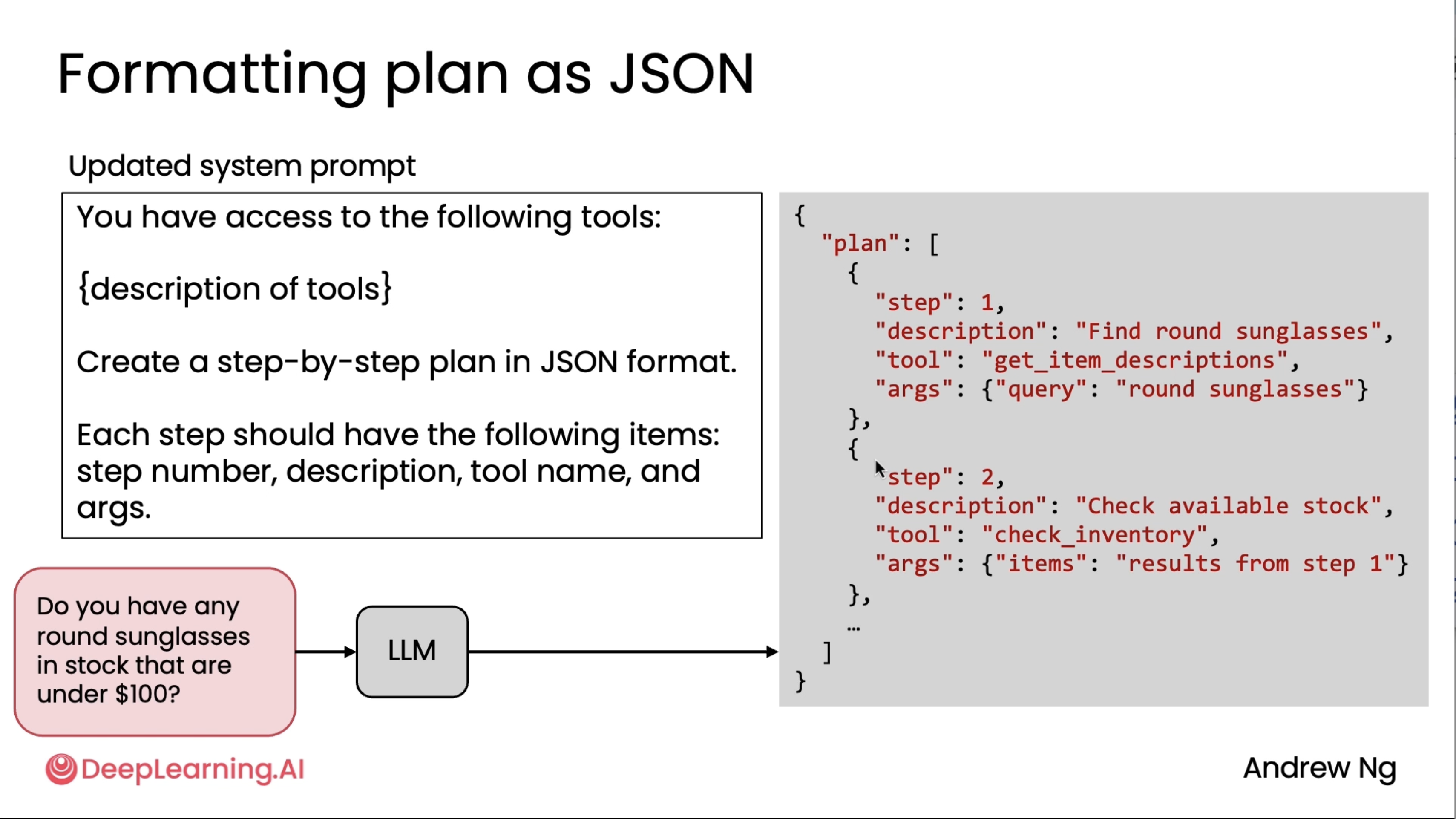
Here, apart from JSON, people also use XML, and last resort is ofcouse via Text.
Planning with code execution¶
Planning with code execution is the idea that, instead of asking an LLM to output a plan in, say, JSON format to execute one step at a time, why not have the LLM just try to write code and that code can capture multiple steps of the plan, like call this function, then call this function, then call this function, and by executing code generated by the LLM, we can actually carry outfairly complex plans. Let's take a look at when you might want to use this technique.
Let's say you want to build a system to answer questions about coffee machine sales based on a spreadsheet with data like this of previous sales. You might have an LLM with a set of tools like these to get column max, to look at a certain column and get the maximum value, so there's a whole answer, what's the most expensive coffee, or get column mean, filter rows, get column min, get column median, sum rows, and so on. So these are examples of a range of tools you might give an LLM to process this spreadsheet or these rows and columns of data in different ways. Now, if a user were to ask which month had the highest sales of hot chocolate, it turns out that you can answer this query using these tools, but it's pretty complicated. You'd have to use filter rows to extract transactions in January for hot chocolate, then do stats on that, and then repeat for February, figure out stats on that, then repeat for March, repeat for April, repeat for May, all the way through December, and then take the max, and so you can actually string it together with a pretty complicated process using these tools, but it's not such a great solution. But worse, whether someone to ask how many unique transactions were there last week, well, these tools are insufficient to get that answer, so you may end up creating a new tool, get unique entries, or you may run into another query, what were the amounts of last five transactions, then you have to create yet another tool to get the data to answer that query.
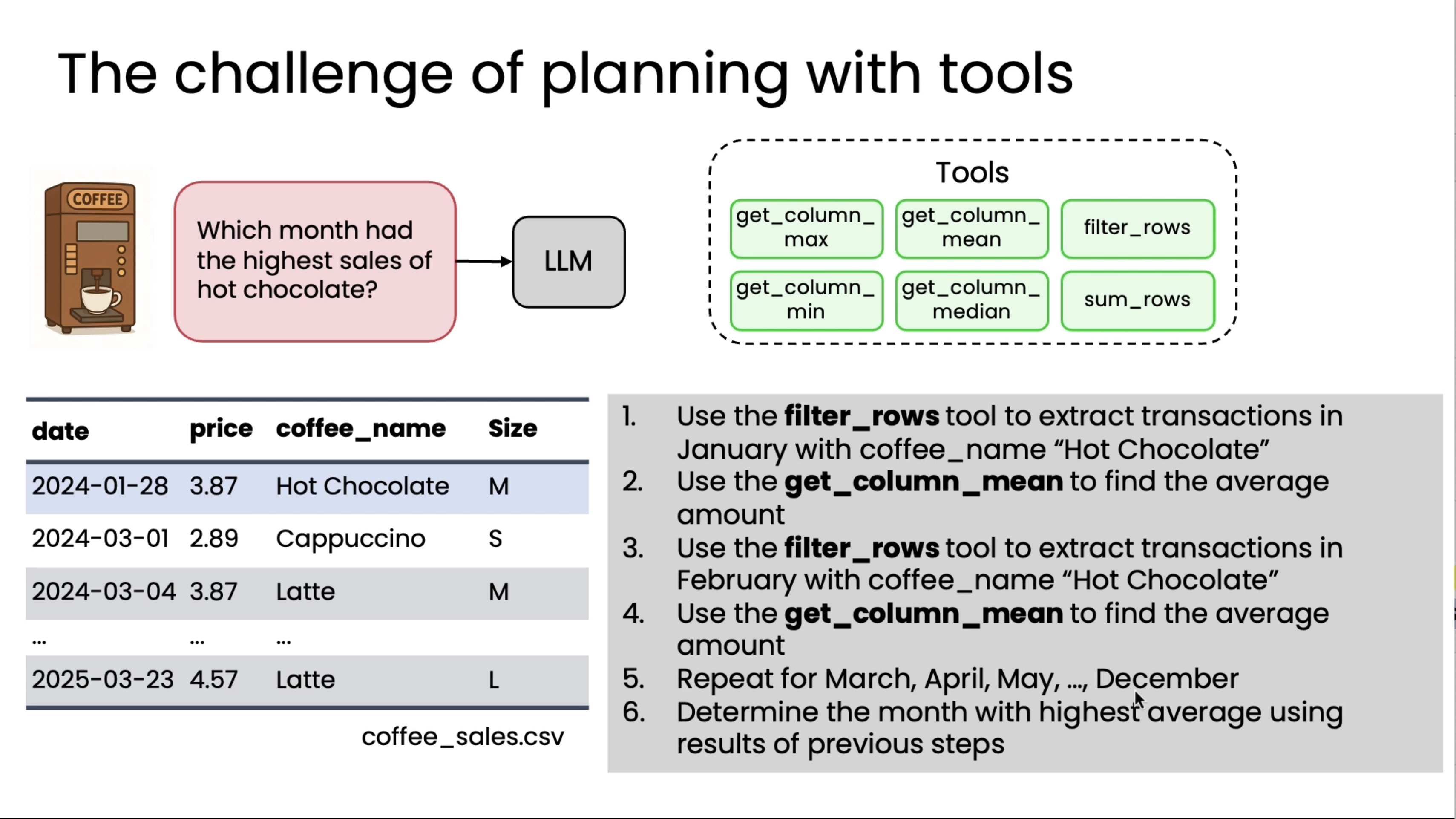
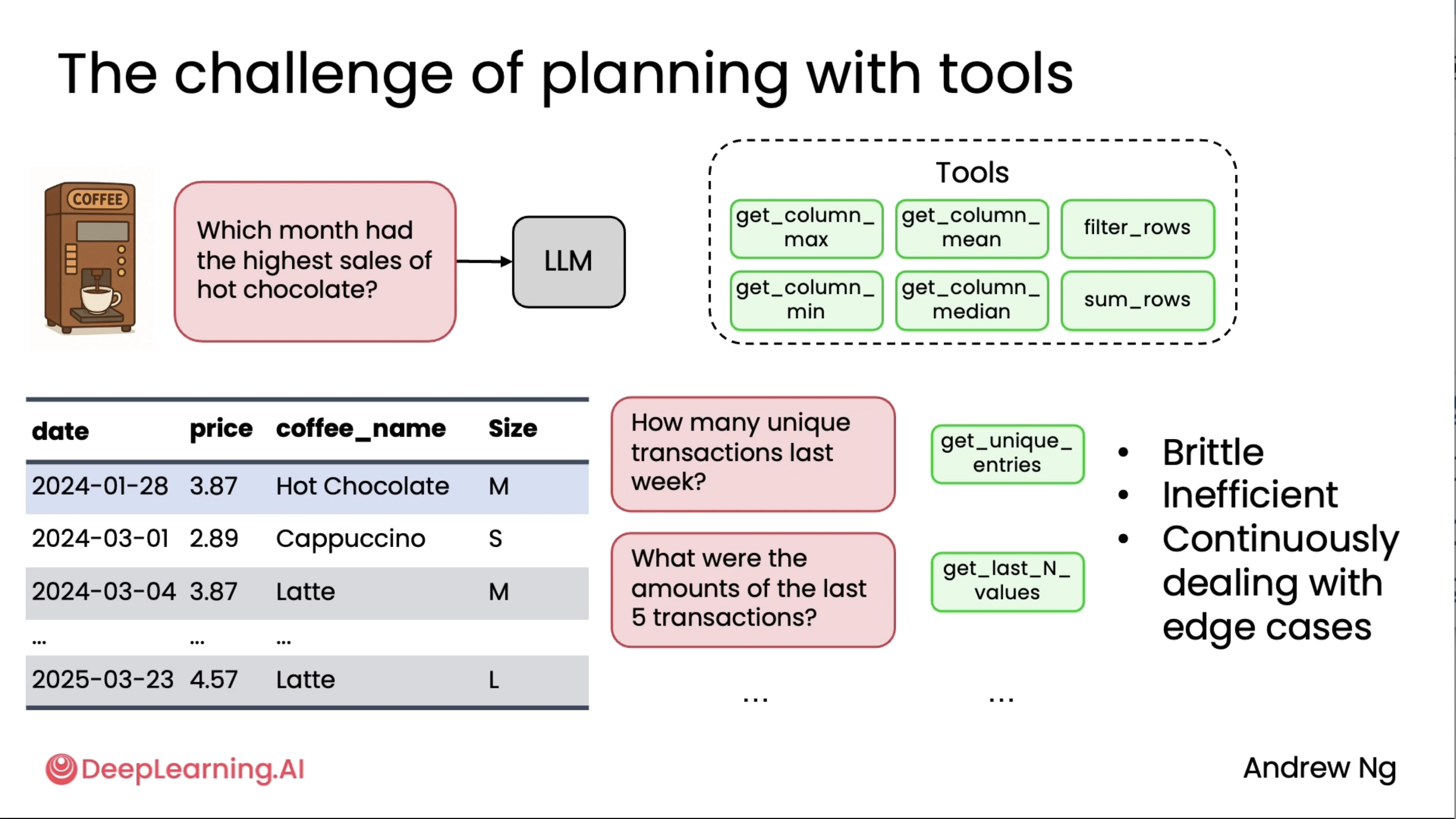
And in practice, we've seen teams, when they run across more and more queries, end up creating more and more and more and more tools to try to give the other enough tools to cover all the range of things someone may ask about a dataset like this. So this approach is brittle, inefficient, and I've seen teams continuously dealing with edge cases and trying to create more tools, but it turns out there is a better way, which is if you were to prompt LLM to say, please write code to solve the user's query and return your answer as Python code, maybe delimited with these beginning and ending execute Python XML tags, then LLM can just write code to load the spreadsheet into a data processing library, here it's using the pandas library, and then here it actually is coming up with a plan.
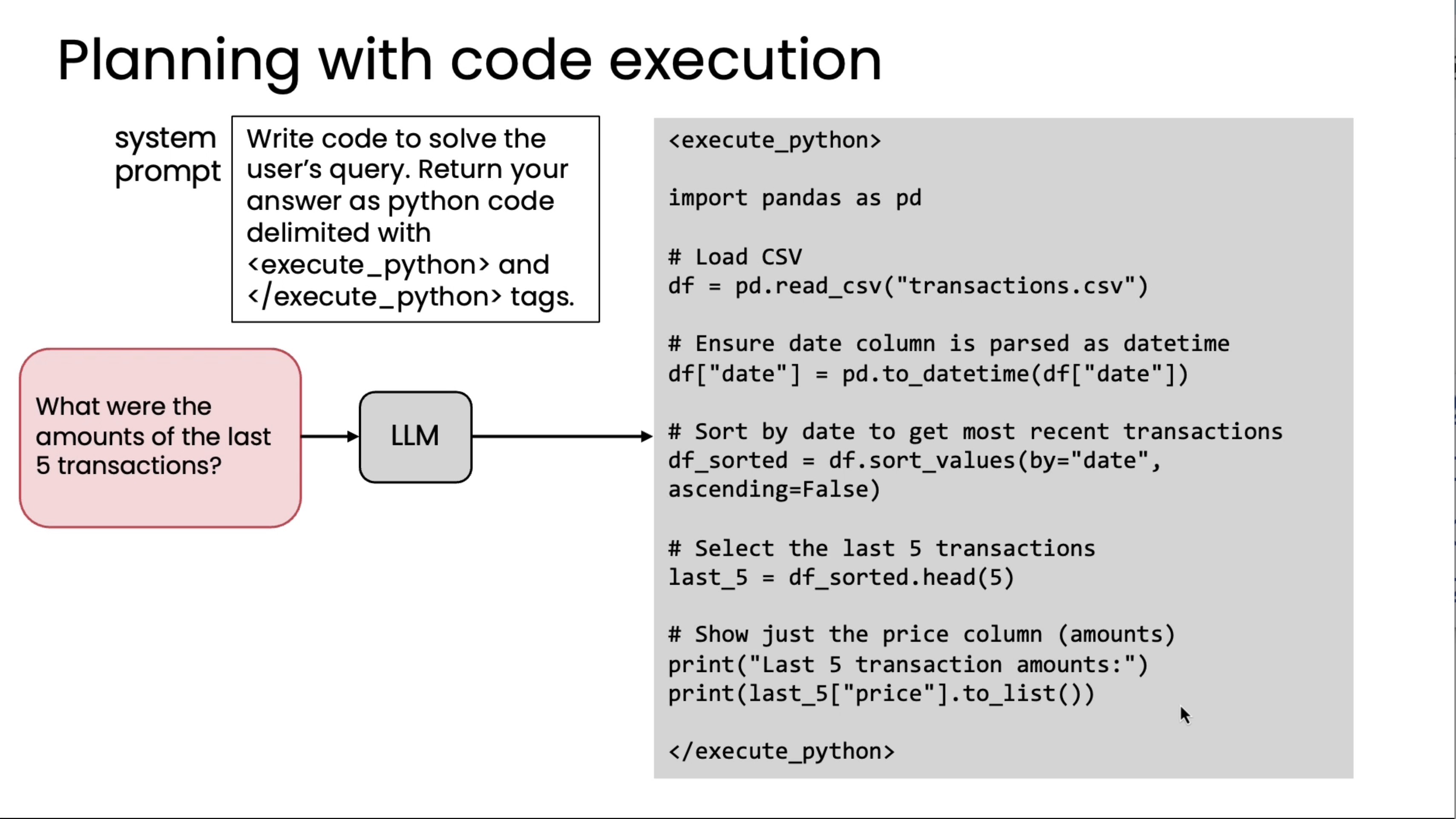
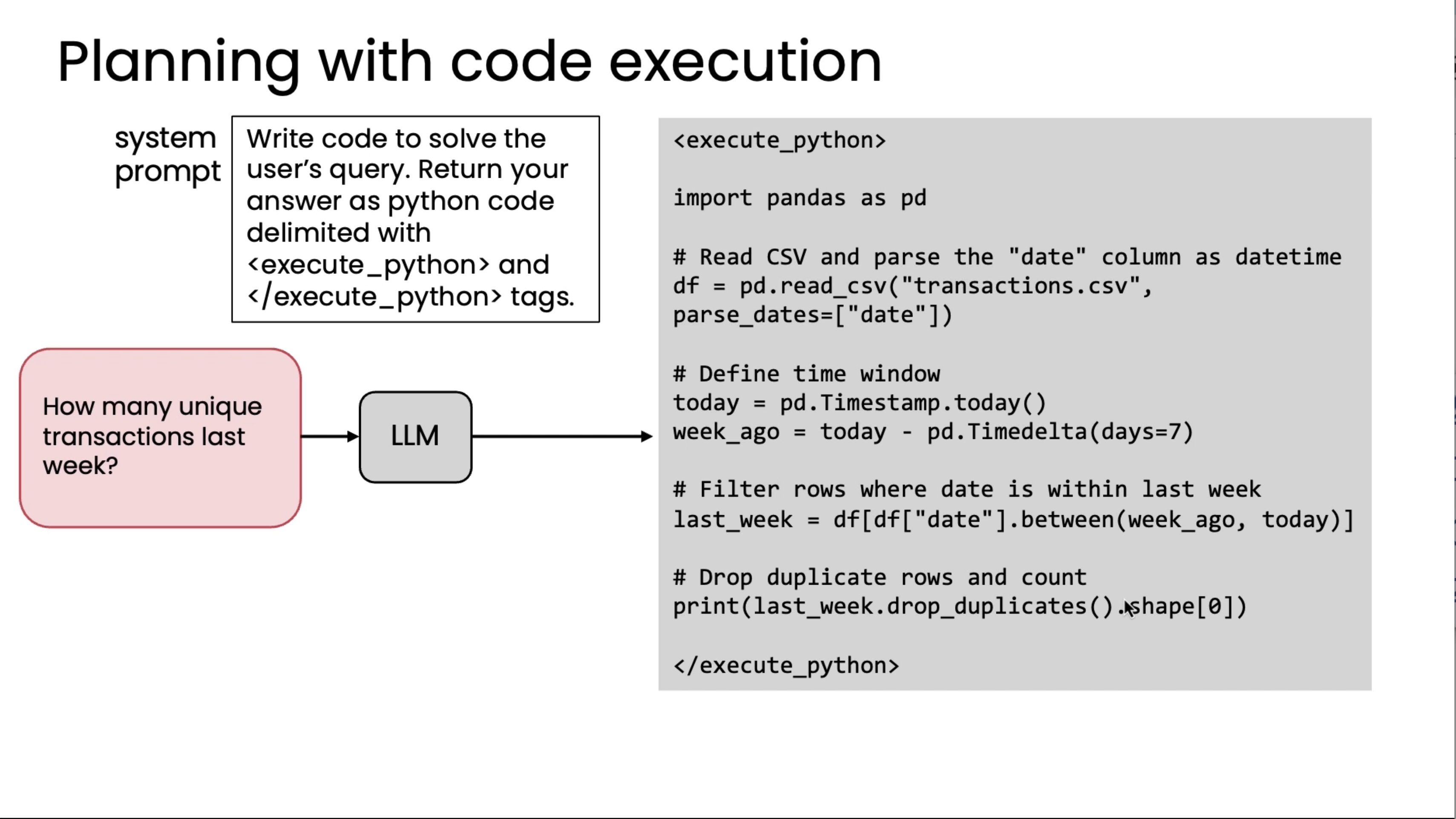
The plan is, after loading the CSV, first it has to ensure the date column is parsed a certain way, then sort by the date, select the last five transactions, show just the price column, and so on. But these are the steps one, two, three, and four, and five, say, of the plan. Because a programming language like Python, and in this example, also with the pandas data processing library imported, because this has many built-in functions, hundreds or even thousands of functions, and moreover, these are functions that the LLM has seen a lot of data on how to call when. By letting your LLM write code, it can choose from these hundreds or thousands of relevant functions that it's already seen a lot of data on when to use, so this lets it string together different choices of functions to call from this very large library in order to come up with a plan for answering a fairly complex query like this.
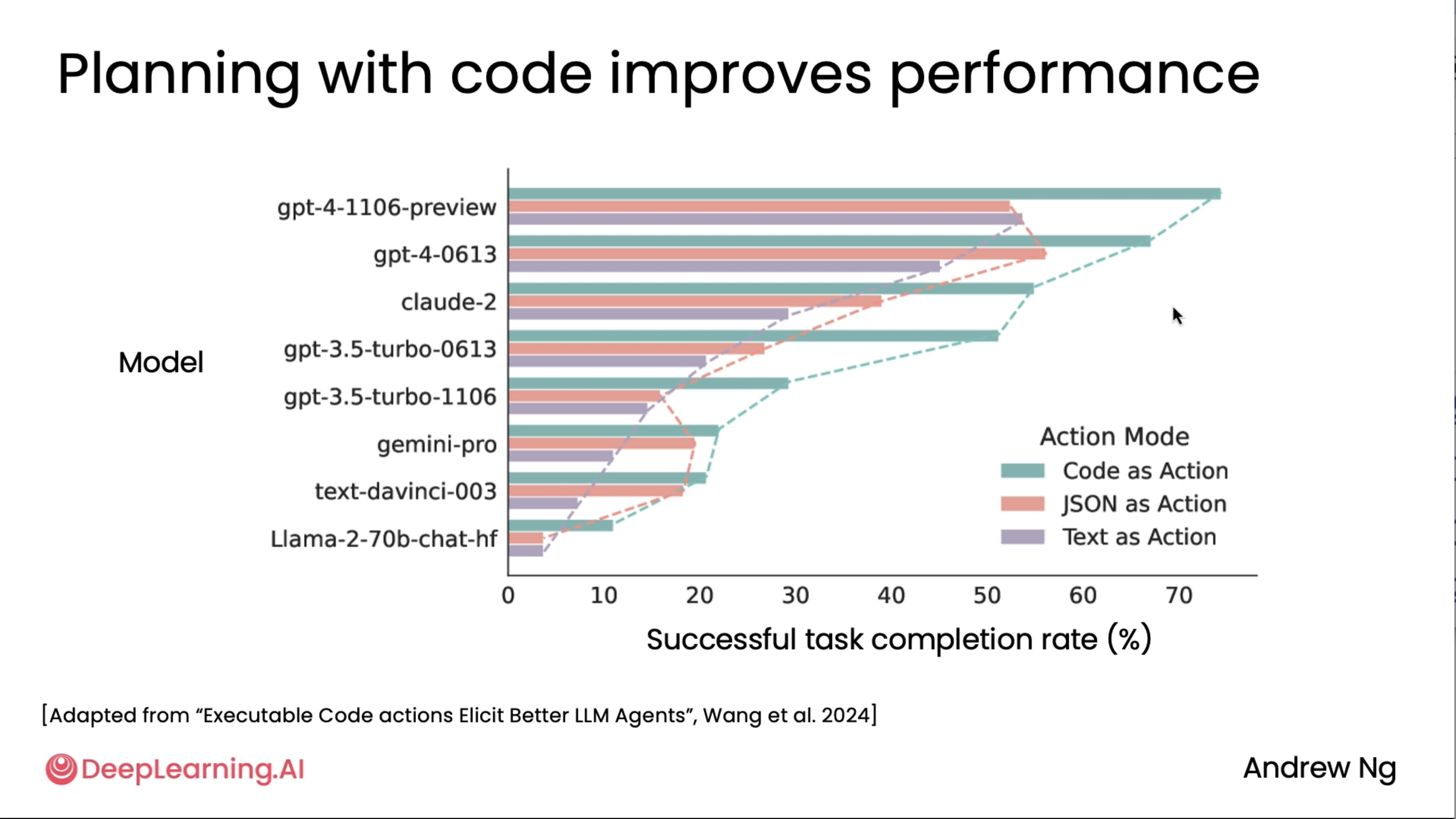
Lastly, it turns out that planning with code works well. From this diagram adapted from a research paper by Xinyao Wang and others, you can see that for many different models for the tasks that they examined, code as action in which the LLM is invited to write code and take actions through code, that is superior to having it write JSON and then translate JSON into action or text. And you also see a trend that writing code outperforms having the LLM write a plan in JSON, and writing a plan in JSON is also a bit better than writing a plan in just plain text. Now, of course, there are applications where you might want to give your custom tools to an LLM to use, and so writing code isn't for every single application. But when it does apply, it can be a very powerful way for an LLM to express a plan.
Multi-agentic workflows¶

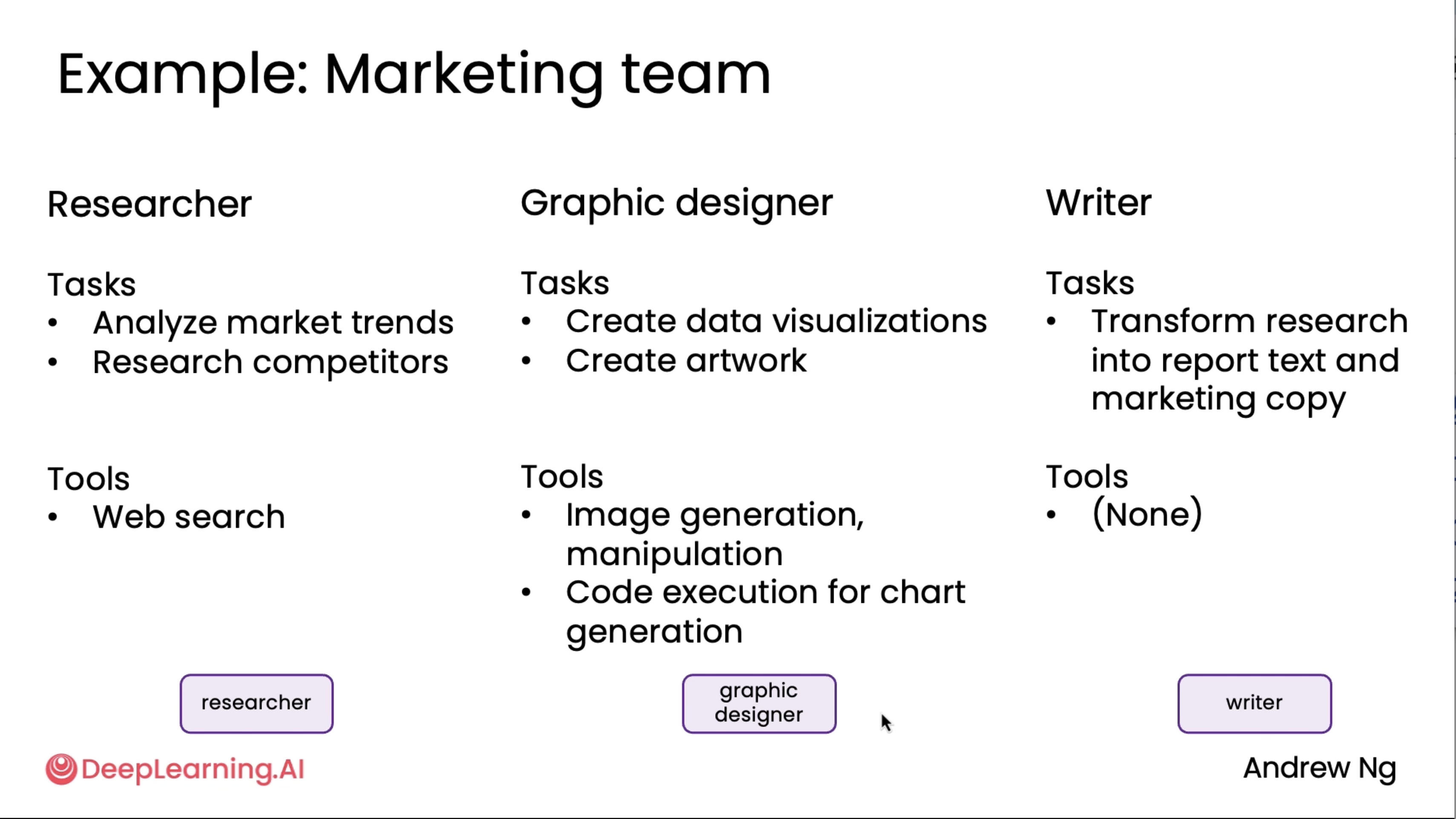
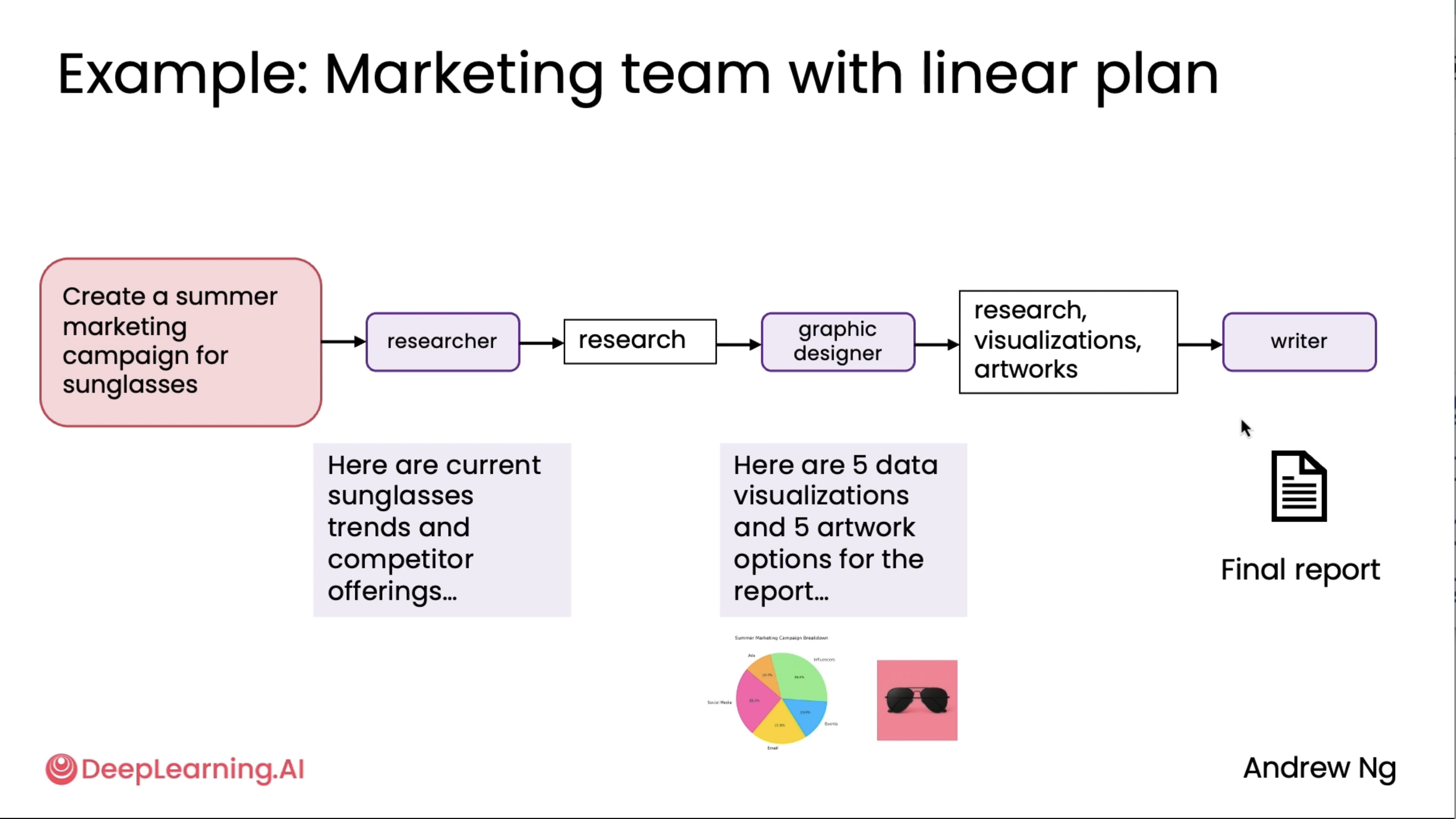
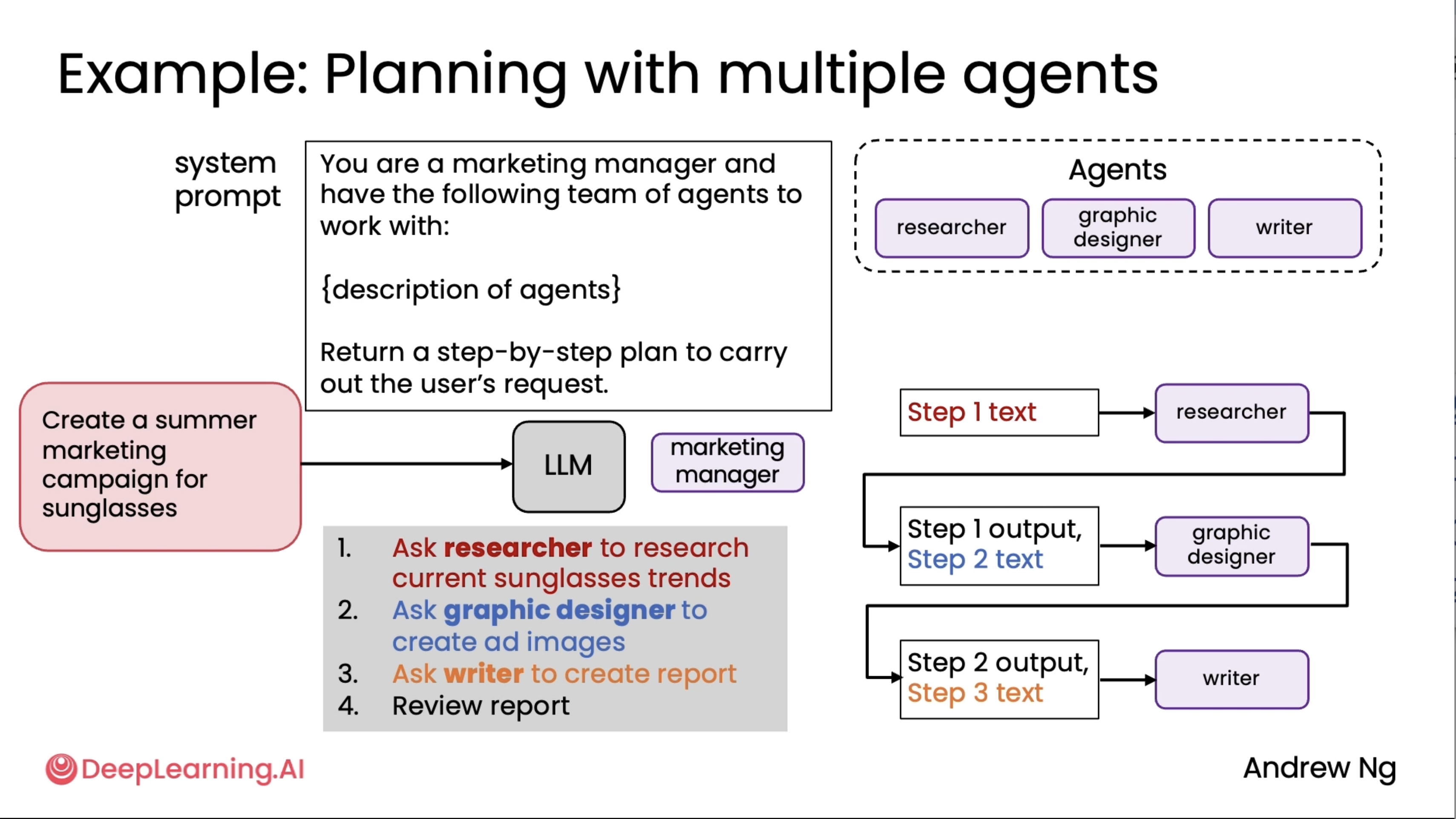
Communication patterns for multi-agent systems¶
This is an extension to the above diagrams^

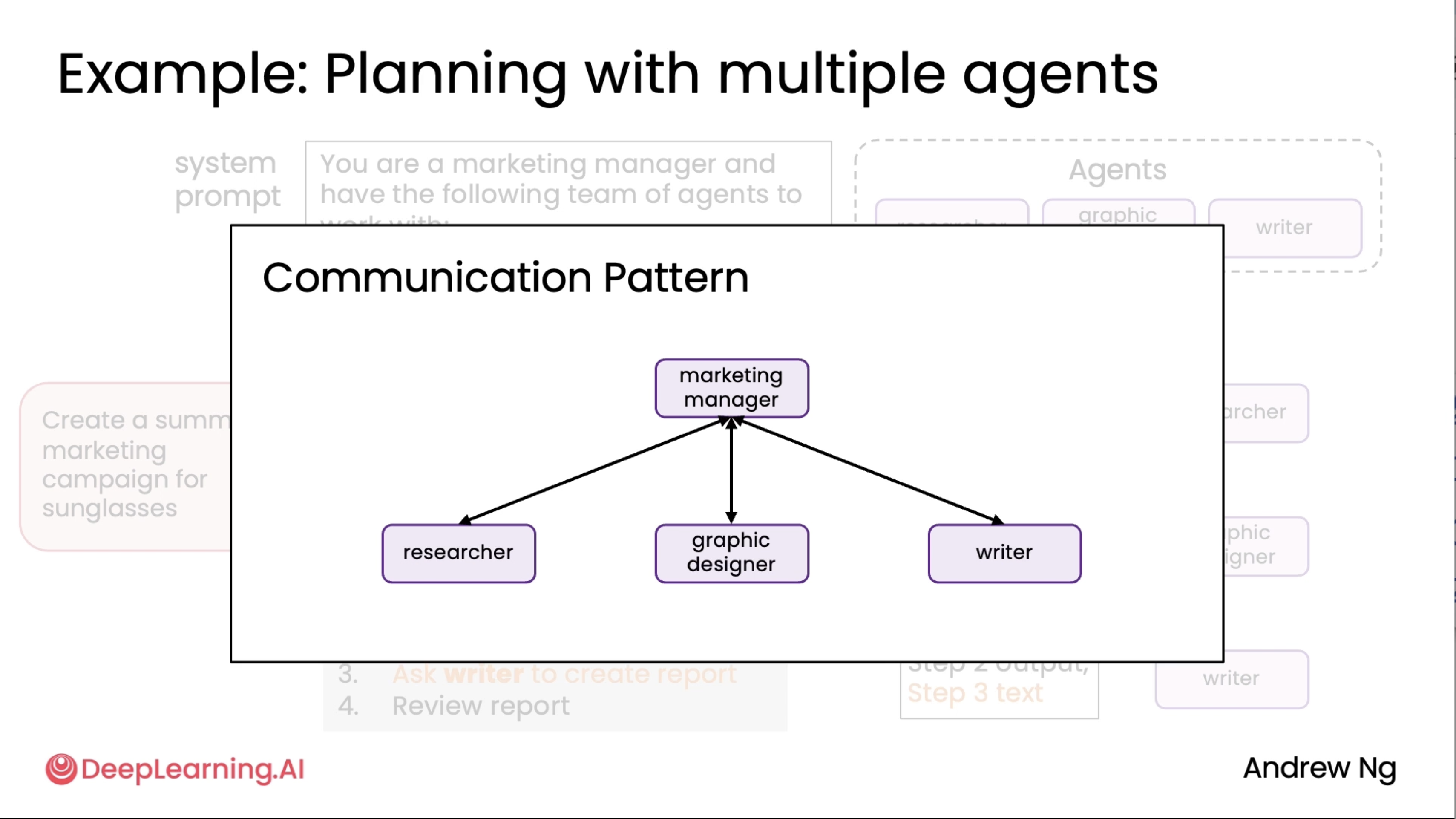
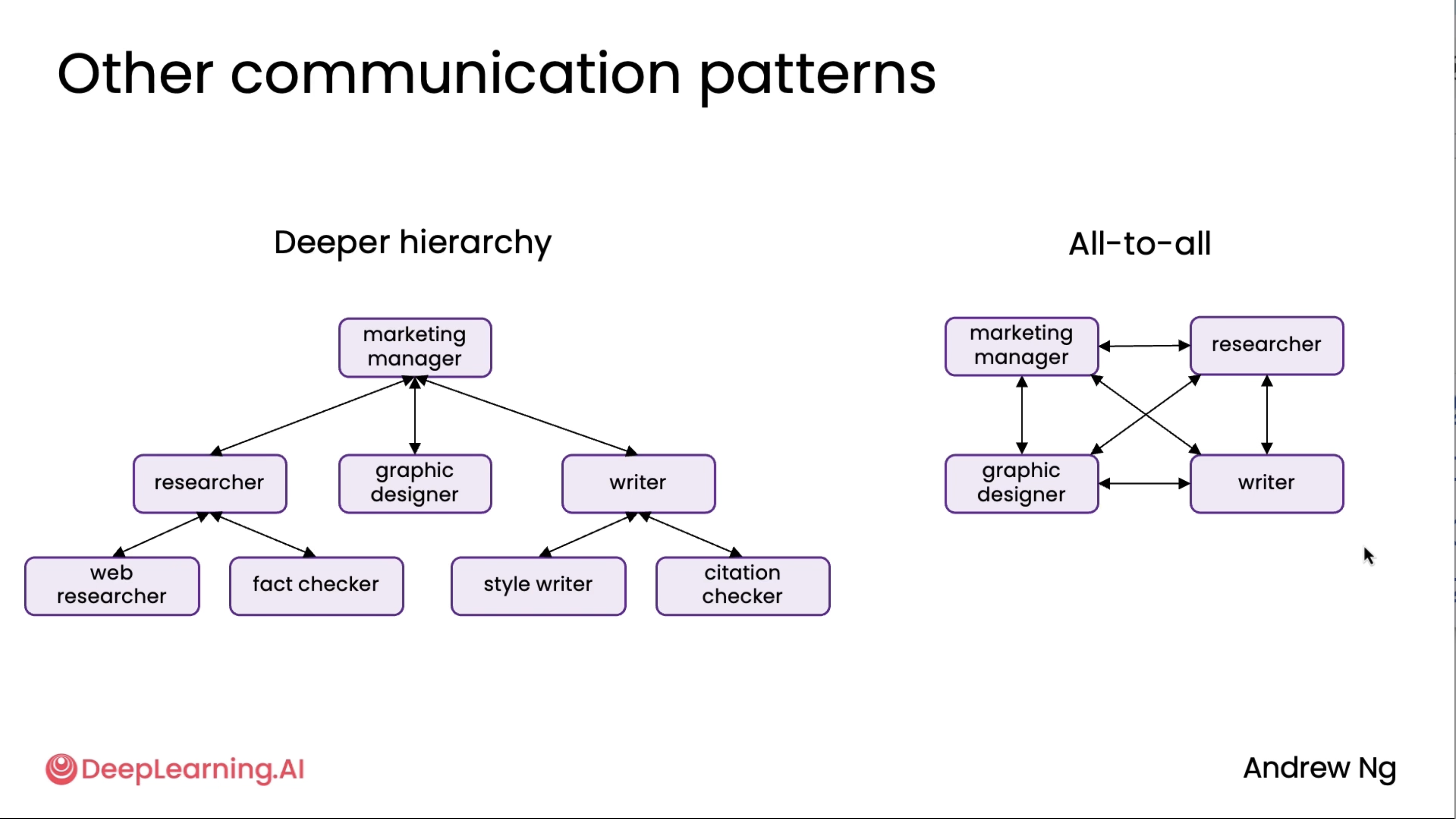
Note: All-to-all approach is not really feasible at the moment so we normally would avoid that.
Code implemetations of the graded/ungraded labs for this can be found in the repo mentioned at the start of this blog!
Final notes¶
That’s the end of this! The course was absolutely amazing, took me about a week to wrap it up, and I’d 100% recommend y’all watch it as well.
You’ll also notice this kind of felt like introductory content, but I think it covers the essentials and gives us a good idea of how to first identify an agentic system and how we can actually label our work as a 'qualified agent' (since there are many projects out there that claim they are actually "agents," haha).
You can find the course on the official deeplearning.ai website and all of the images above are credited to them. I hold no ownership of them and am only using them for purely educational and informational purposes (and am not commercializing this content in any way).
Thank you for reading, now we move on to the next one! Happy learning :)